
1. File system
1-1. File system의 정의
파일이란 무엇일까? 파일은 Byte의 배열 혹은 연관된 정보의 집합이다. 다음은 File과 Address soace를 비교한 표이다.

File system은 File과 Physical disk block간의 Mapping을 제공한다. 따라서 사용자는 File이 저장된 위치를 알 필요 없이 사용 가능한 것이다(Independence)(File 안다면 Data block 고려할 필요 X) 또 다른 관점으로 file system은 Disk에 들어가 있는 File 전체를 총칭한다. File system에 따라 File들의 배치나 구성이 달라질 수 있다.(윈도우는 C를 기준으로, 리눅스는 /를 기준으로 대충 이런거)
그럼 파일은 어떤 것을 의미해서 Data block을 알 필요가 없다는걸까? 다음은 File이 저장하는 attribute인 Metadata다.

이외에도 Time, Data, User Information등이 존재한다. 이러한 File의 정보가 Directory Structure에 저장된다.
그리고 이러한 파일을 조작하기 위해서 다음과 같은 연산이 존재한다.

여기서 눈여겨 볼 만한 것은 File seek의 Current-File-Position pointer이다. 이는 File에 대해서 process(읽기 쓰기 등)가 어디까지 작업했는지 기록하는 포인터이다.
1-1. File system에서의 File관리 (Open과 Close)
Filesystem에서 파일의 Open과 Close를 어떻게 관리할까? 리눅스에서 여러개의 프로세스가 동시에 같은 파일을 조작할 수 있다. 이때 서로 다른 프로세스는 다른 프로세스가 동일한 파일을 읽든 말든 동일한 결과를 보장해야한다. 따라서 Process 별로 file에 대한 정보를 유지할 필요가 있다. 또한 Filesystem에서 File 자체를 관리해야 할 필요가 있다. 따라서 두 형태의 Open fiile table을 유지한다
-a. Per Process Table : 각 Process에서 유지하는 state (예를 들어 위의 File pointer)
-b. System-wide table : Process independent information (예를 들어 Access Date, File Location, Open count)
-> 여기서 Open count는 파일을 읽고 있을 때 파일을 삭제하지 못하는 기능 등을 지원하기 위함이다.
1-2. 파일접근
파일 접근은 순차 접근과 임의 접근이 있다. 순차 접근은 File에 있는 정보에 대한 접근이 Record의 순서대로 이루어지는 접근 방식이다. (마치 링크드 리스트 처럼 순차만 가능) 임의 접근의 경우, File의 어떠한 위치라도 바로 접근하여 Read나 Write를 수행할 수 있는 접근 방식이다. 당연히 후자의 방식이 현재 사용된다.
1-3. Filesystem의 구성
다음은 전형적인 file system의 구성이다.

.그리고 파일 시스템은 다음과 같이 계층화되어 있다.

계층에 대한 예시를 살펴보자. 우선 Application이 file에 대한 연산을 시행했다고 하자. 이 연산은 Virtual file system에 전달된다. 이 Virtual file system에서 실제로 그 파일을 관리하고 있는 file system에 연산을 전달한다 이렇게 하는 이유는 File system을 구현하고자 하는 장치가 다양할 수 있고, 한 System에 1개 이상의 File system을 사용 가능해야 할 필요가 있고, 계층화 된 구성을 통해 File system에 유연성을 제공하기 위함이다.
1-4. Mount
파일을 연다 -> Open
파일 시스템을 사용한다(접근하고자 하는 물리적인 데이터가 물리 장치에 저장되어 있고 이에 접근하고자) -> Mount
Mount를 하면 Mount를 한 폴더를 통해 장치에 저장된 물리 데이터에 접근 할 수 있게 된다. 이렇게 Mount를 사용하는 이유는 Distributed FS로 확장이 용이하기 때문이다.

분배된 Filesystem을 하나의 시스템에서 유연하게 사용할 수 있게 된다. (마치 하나의 디스크인 것 처럼)
2. Directory
파일이 많아짐에 따라 모든 File들에 대한 정보를 가지는 Node들의 집합인 Directory structure를 필요로 하게 되었다. (Directory structure와 file은 모두 Disk상에 존재) 지금부터 Directory structure이 어떠한 구조를 가졌는지, 어떻게 발전했는지 알아보자.



Dangling pointer에 대한 처리가 중요하다! 하나 삭제하면 그 파일에 대한 모든 접근 방법을 삭제해줘야함

루프를 없애기 위해 위의 Cycle이 없도록 보장하는 방법을 진행
3. File구현
대부분의 시스템에서 Disk를 Memory의 Frame처럼 일정 Block 크기로 쪼갠 후 입출력 단위로 사용한다. 이를 Disk block이라고 한다. File의 데이터를 실제로 저장하는 이 Disk block의 위치 정보를 어떻게 저장할지가 File 구현에 중요한 요소이다. 운영체제 마다 각기 다른 방식으로 File의 Data block 정보를 관리한다. 다음은 그의 예시이다. (I-Node를 현재 대부분 사용한다)
1. Contiguous allocation
File을 물리적으로 연속된 Dsik block에 저장하는 것이다. 구연이 간단하고, 전체 파일을 한번에 읽을 때 성능이 좋다. 하지만 연속된 block으로 저장해야해서 저장이 비효율적이다.
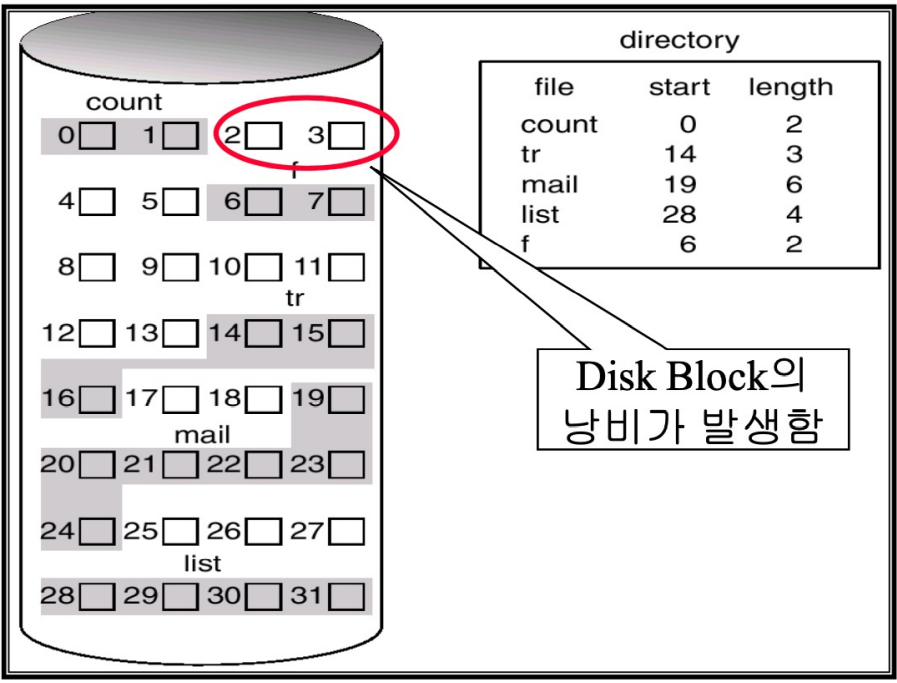
2. Linked list allocation
Disk block을 linked list로 구현하여 File을 표현하는 방법으로, 공간 낭비 없이 File의 Data block이 Disk의 어디든 위치 할 수 있다는 장점이 있지만, linked list이므로 block이 순차 접근만 가능하다. 즉, Random access가 불가능하다. 게다가 Linked list를 위한 block의 포인터(주솟값) 때문에 Data block(4KB)이 저장하는 데이터의 용량이 2의 배수가 아닐 수 있게 된다(4KB-K). 하지만 이는 매우 문제인데, 대부분의 Read write하는 Data의 크기가 2의 배수이기 때문에 성능 측면에서 뒤쳐질 수 있기 때문이다. 여기서 포인터란 disk block pointer로, Dat block의 갯수에 의해 결정된다.

3. Linked list allocation using an index
Random access를 위해 각 Index에 대한 정보를 모아둔 Block을 만들고 이를 참조하는 형태로 구현되는 방식이다. Random access시 Data block의 위치를 바로 찾아 갈 수 있기 때문에 Linked list allocation보다 빠르다는 장점이 있지만 하나의 Data block에 인덱스를 전부 집어넣다 보니, 최대 File의 크기가 고정된다는 단점이 존재했다.

4. I-nodes
File에 대한 Data block index를 Table형태로 관리하는 방법이다. (다만 Multi-level table로 관리) I-node의 구성요소는 다음과 같다. 1) File에 대한 속성을 나타내는 Field(맨 처음에 봤던 필드들), 2)작은 크기의 File을 위한 Direct index, 3)File의 크기가 커짐에 따라서 요구되는 Data block들을 저장하기 위한 Index table들(Multi-level table)

4. Directory의 구현
Directory entry란 디렉토리를 표현하기 위한 자료구조이다. 이 자료구조는 데이터를 저장하는 방식에 따라 달라질 것이다. 이번 방식에서는 MS-DOS(Linked list allocation)와 UNIX(I-node) 두가지 구현 방법에 대해서 알아보자.
4-1. MS-DOS(Linked list allocation)

첫 Block의 number만 알면 포인터로 나머지 block에 접근 가능하다.
4-2. UNIX(I-node)
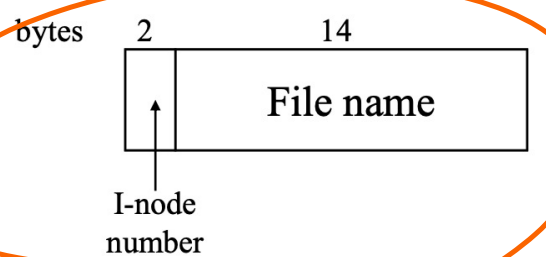
attribute, ownership 등과 같은 정보들이 File의 I-node 자료구조에 직접 저장되어 있기 때문에 단순한 구조를 띈다.

/usr를 찾는 과정에서도 볼 수 있듯이 결국 디렉토리의 정보(포함하는 파일들에 대한 이름과 inode number들)도 파일로써 관리된다.
5. Protection
파일에 대한 부적절한 접근을 막는 것이다. 다음과 같은 Access type이 있다. Read / Write / Execute / Append / Delete / List(File의 속성이나 이름의 내용) 이 친구들이 어떻게 관리될까? 다음은 그 예시이다. 하나의 비트가 Access type을 맡고 이를 병합하여 하나의 값으로 권한을 나타낸다. 이 권한은 사용자의 타입에 따라서 달라지므로, 각 사용자 타입에 대한 접근도 나눠서 관리해야 한다.

'학교 공부 > OS' 카테고리의 다른 글
| 운영 체제 (Operating System) (0) | 2021.11.30 |
|---|---|
| 운영 체제 (Operating System) - Memory Management (2) (0) | 2021.11.30 |
| 운영 체제 (Operating System) - 동기화 (2) (0) | 2021.11.30 |
| 운영 체제 (Operating System) - 9. 동기화 (1) (0) | 2021.11.29 |
| 운영 체제 (Operating System) - Thread (0) | 2021.11.29 |