
Why Graph?
관계, 상호작용 등 추상적인 개념을 시각화 하고 다루는데 적합하다
복잡한 문제를 간단한 표현으로 단순화 할 수 있다.
Why GNN
BFS, DFS, Dijkstra 등 classic한 그래프 알고리즘들을 사용하기 위해서는 입력그래프에 대한 사전 지식이 필요하다. 따라서 그래프의 정보를 다루는 그래프 레벨에서의 예측이 불가능하다. -> 그래프에 직접 적용하여 그래프 레벨 예측을 할 수 있는 GNN 필요성 대두
// 입력 그래프에 대한 사전 지식? :
// 그래프 레벨 예측? :
GNN
오버뷰
입력(모든 점들과 그 점들의 상태) -> Neural network -> 출력(Prediction, Node embedding)
입력
점은 연결에 의해 정의된다
추론
NLP에서 Recurrent하게 hidden state를 이용해서 추론을 이어나가는 것과 유사하다.

현재 vertice v에 대하여 v와 연결된 모든 vertice들(u)을 입력으로 하는 Neural network(function f)를 돌리는 것이다. 이때 입력으로 랜덤하게 초기화된 h^(0)를 NLP의 RNN과 같이 순환하며 상태를 갱신하여 최종 Hidden state를 도출한다.
// Graph의 연결을 Sequence data처럼 처리하는 아이디어 인듯 하다. 이렇게 함으로써 전체 데이터에서 sub graph의 contextual data를 포함하는 embedding을 만드는 방식으로 추측된다. (이러한 contextual data를 포함하면 어떤 부분에서 추론이 좋아질까? -> 뒤에 나오는 Scene graph generation by interative message passing 처럼 각 노드(여기선 object)간의 관계를 단순 Euclidean distance를 쓰는 것 보다 더 정확하게 나타내는 것이 아닌가 한다.
아래는 Hidden state의 갱신 과정이다.
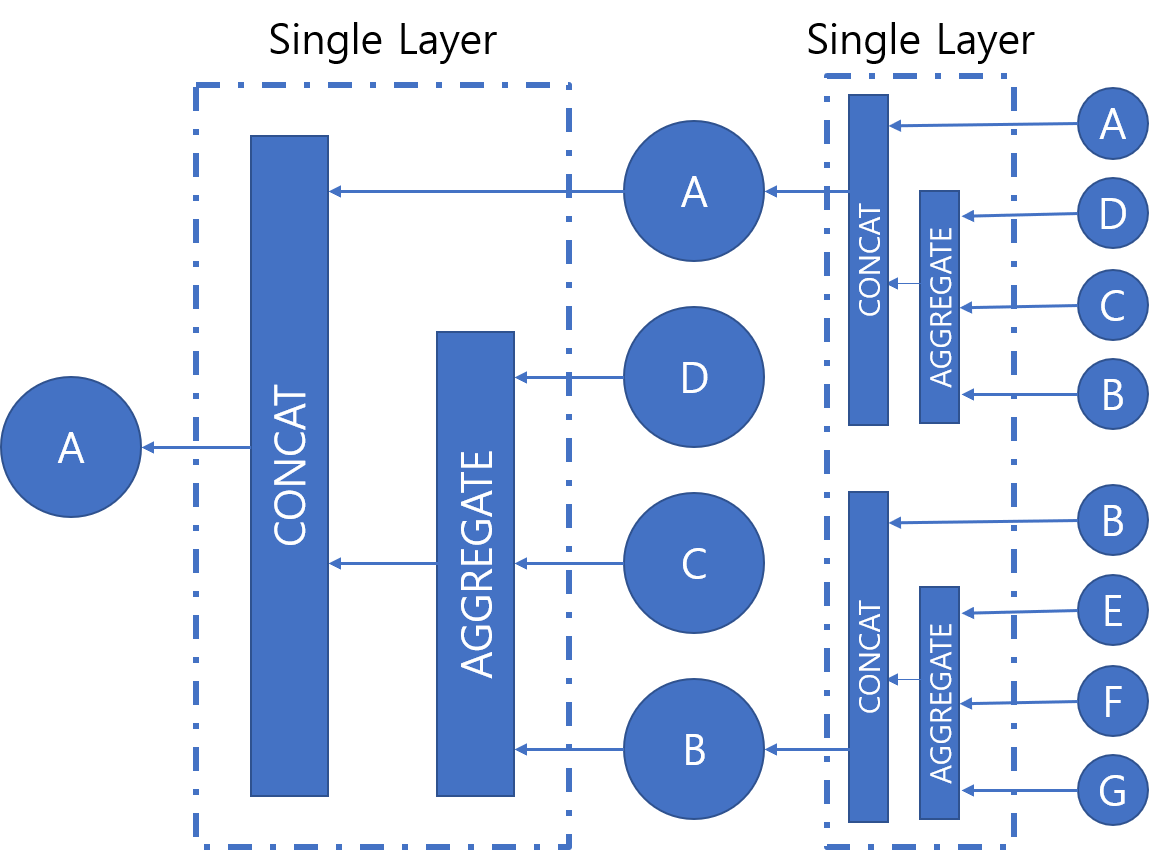
어떤 타입의 그래프를 받아 어떤 정보를 추출할지에 따라 나뉨, 대표적으로 1)Recurrent Graph Neural Networt 2)Spatial Convolutional Networt 3)Spectral Convolutional Network에 대해 알아보자.
Recurrent Graph Neural Networt
Background

따라서 k번 업데이트를 반복하면 마지막 상태를 결정할 수 있다.
업데이트? : 주변 점과 연결된 선으로 상태를 업데이트 하는 것 (그래프 내의 자신의 문맥 정보 학습?)
상태 업데이트를 위한 입력들과 함수

인자 설명
l: feature 의미
n : 점을 의미
x : 상태를 의미
co[n] : 점(n)과 연결된 선들을 의미
ne[n] : 점(n)과 연결된 점들을 의미
예시

이렇게 추론 결과를 이용하여 결과(o)를 다음과 같이 도출하자면 다음과 같이 output이 도출된다.
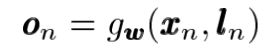
아마 여기서의 g는 Gated recurrent unit으로 추측된다. LSTM
이를 비전에 적용한다면?
Spatial Convolutional Network
CNN이 Convolution으로 Receptive field 내의 픽셀에 대해 정보를 추출하는 것이라면 이는 그래프를 구성하는 점에 대해 정보를 추출하는 것이다.

// 점들의 갯수라던가 distance라던가 다 다를텐데 어떠한 기준으로 점을 선택하는거지? 그리고 갯수를 고정해야할텐데 이에 대한 문제점은 없나?
그래서 어떤게 돼?
Node classification (Node embedding으로 점을 분류하는 문제), Link prediction (점들의 관계[연결성, 연관성]을 예측하는 문제), Graph classification (그래프를 여러개로 분류하는 문제) 등이 가능하다. 게다가 문제를 XAI관점에서 논리적으로 주장할 수 있다. (Graph에 장점을 다시 떠올리면 이해가 된다. Graph로 점들 간의 관계를 정의 및 표현할 수 있기 때문)
이러한 장점을 비전에 녹여낸 결과들
1. Scene graph generation by interative message passing

이미지로 제목을 한번 소분해보자. Scene graph generation { by interative (message passing) }
우선 목적인 Scene graph generation은 이미지(Scen)에서 추출한 Feature(혹은 classification한 결과)를 Graph로 generation하는 것이다. 이를 이미지에서 edge feature와 node feature를 추출한 이후, 자신의 feature space에서의 graph로 표현한 다음, interative한 message passing(Gated Recurrent Unit)으로 관계를 도출하는 방식이다. (Transformer의 Attention처럼 similarity를 뽑는듯)
// Node가 무엇인지, 어떻게 Edge와의 관계를 뽑아낼 수 있는건지
2. Image generation from secne graph
반대로 Scene Graph에서 관계 찾고, 그 관계에 따라 이미지를 만드는 것도 있다.

어떻게 이미지를 만드는지는 Image geneartion파트이므로 생략
3. Graph-Structured Representations for Visual Question Answering
이미지와 텍스트 매칭으로 볼 수 있는 Visual question answering에도 적용할 수 있다. 이미지에서 affine을 추출하고, 텍스트에서 word간의 embedding을 추출한다. 이렇게 추출된 image의 embedding들은 feature space에서 spatial relationship으로 edge를 만들어 graph를 형성할 것이고, 추출된 word embedding들은 syntatic dependency로 edge를 정의한다. 여기서 각 Node와 Neighborhoods를 입력으로 하는 Graph processing(Gated Recurrent Unit)으로 Graph 내 각 노드가 contextual data를 갖게한다(연관된 객체일수록 비슷하게, 아닐수록 다르게). 이렇게 추출된 objects graph의 node와 wods graph의 node들을 ((N X N) X M)으로 pairwise 매칭하고, Attention기반의 weight를 곱하여 최종 prediction을 만든다..

눈 여겨볼만한 점은 Scene에서 embedding을 뽑고, 뽑힌 embedding간의 spatial relationship으로 graph를 정의한 것과 추출한 데이터 타입(이미지, 문장)이 다른 graph들을 병합하여 similarity를 뽑아내는 점이 신기해보인다
Reference
GNN 소개 — 기초부터 논문까지
이 글은 Shanon Hong의 An Introduction to Graph Neural Network(GNN) For Analysing Structured Data를 저자에게 허락받고 번역, 각색한 글이다.
medium.com
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kks227&logNo=221228019936
셋 커버: Primal-dual method
Primal-dual method는 primal, dual을 동시에 관찰하면서 솔루션을 찾아내는 각종 테크닉을 말하는데 그 ...
blog.naver.com
http://www.secmem.org/blog/2019/08/17/gnn/
https://thejb.ai/comprehensive-gnns-2/
Graph Neural Networks 개념정리 2 - Recurrent GNN
소개
thejb.ai
'ML' 카테고리의 다른 글
| DIP10.1~10.2 Edge-based Segmentation (2) (0) | 2022.03.04 |
|---|---|
| SuperGlue 리뷰 (0) | 2022.02.10 |
| Feature matching 피드백과 목표 (0) | 2022.02.09 |
| DIP 9. Morphological Image Processing - 2. Morphological Reconstruction (0) | 2022.02.08 |
| DIP 9. Morphological Image Processing - 1. Preliminaries (0) | 2022.02.07 |