
1. 접근 방법
SOLO는 instance categories라는 개념을 도입함으로써 instance segmentaion을 새롭게 보았다. instance안의 픽셀에 그 instance의 위치와 사이즈에 따라서 카테고리를 배정함으로써 single shot classification-solvable problem으로 기존의 문제를 전환하였다
1. single shot classification-solvable problem?

기존에는 affirny relation을 바탕으로 vector를 만들고 그 vector를 바탕으로 instance를 판별하는 bottom-up방식이나 mask rcnn과 같이 RoI를 만들고, 그 RoI에서 Instance를 찾는 top-down방식을 사용하였는데 전자는 너무 연산적으로 비싸고, 후자는 accurate bounding box detection에 너무 의존하거나, pre-pixel embedding learning이나 group grocessing에 너무 의존하는 경향이 있었다.
반면에 SOLO에서는 박스나 추가적인 pixel pairwise relation을 이용하는 대신 full instance mask annotation를 관측함으로써 직접 segment instance mask를 하고자 한다.
2. object instance를 구분 짓는 요소는?
가장 처음에 출발한 질문은 이미지의 object instances간의 근본적인 차이가 무엇이냐는 것이다. coco dataset을 예로 들자면 98.3%의 이미지 내 객체들의 쌍의 중심 거리가 30픽셀보다 컸고, 나머지 1.7%의 대해서는 40.5%의 객체간의 크기 차이는 1.5배 이상 컸다고 한다.
분석 결과로 불 수 있듯이, 2개의 인스턴스를 구분짓는 요소는 서로 다른 center location이나 서로 다른 size로 볼 수 있다. 그럼 이 center location이나 객체의 크기로 직접 객체를 구별한순 없을까?라는 의문을 갖고 만든 모델이 SOLO이다. 본 논문을 이를 위해서 instance categories라는 개념을 소개하고자 한다. (즉, quantized center locations과 object sizes가 객체를 구분짓는다)
3. Locations
이미지는 S X S의 그리드 모양으로 S^2개의 셀로 나뉠 수 있다. 객체의 중심 좌표에 따라 객체는 하나의 grid cell에 포함될것이다. output이 될 S^2개의 output chennel은 center location categories와 그에 맞는 chennel map은 객체가 속한 위치에 해당하는 instance mask를 예측해야한다. 그렇기 때문에 Mask를 위해서 gemoetric 정보는 height x width크기의 spatial matrix에 유지되어야 한다. 이를 통해 SOLO는 Dense sliding-sindow방식을 사용하는 DeepMask나 TensorMask와는 다르게 SOLO는 box location이나 사이즈에 제한없이 정확한 크기의 mask를 만들어낸다. 근본적으로 instance location category는 instance의 object center의 위치와 유사하다. 그러므로 각 픽셀을 instance location category로 분류하면 이는 곧 latent space에서 객체 중심의 픽셀을 예측하는 것과 같다.
이 부분이 가장 중요하다. instance를 구분 짓는 요소가 box가 아닌, 객체의 중심이 될 수 있다고 이야기 했었다. 그런데 중심 좌표 자체를 regression하기보다는, 그 중심이 속한 grid cell을 classification하겠다는 것이다. 뒤에 서술하겠지만, 가령 training data 중 하나가 (center_x, center_y)와 (w,h)의 크기를 가질 때 (cetner_x, cetner_y, ϵw, ϵh)를 center region이라고 하고, 그 부분을 positive sample로써 분류하여 center gird에 대해서 학습하는 것이다. 예시로 test time때 하나의 사진이 들어온다면 instance의 중심에 가까운 grid cell일수록 그 grid cell에 속한 객체가 사람이라고 확신하는 정도는 늘어날 것이다.
여기서 location예측 문제(Regression)를 분류 문제로 바꿔준다는 점이 중요한데, 분류 문제는 조금 더 직접적이고, 모델이 고정된 channel의 수에서, grouping이나 learning embedding과 같은 post-processing에 의존하지 않으면서 객체의 수를 다양하게 하기에 쉽기 때문이다. (Regression문제에 비해 Classification 문제가 갖는 장점을 활용하겠다는 것)
4. Size
다른 크기를 갖는 instance를 구분하기 위해서 FPN(Feature Pyramid Network)을 사용했다. 다른 사이즈, 다른 feature map의 level에 배정할 수 있게 된다. 그러므로 모든 object instance는 분리되고 instance categories로 분류가 가능해진다. ( YOLO의 단점이었던 작은 객체의 detection도 FPN을 통해 해결할 수 있었다고 한다.)
FPN이 이미지에서 다른 크기의 객체를 발견하기 위해 디자인 되었음을 상기해보자. 본 팀은 경험적으로 FPN이 본 모델에 매우 중요한 요소이고 segmentation performance(특히 객체의 크기가 다양한 점에서)에 매우 큰 영향을 끼침을 확인하였다.
5. 정리
SOLO를 이용함으로써 mask annotations만으로 instance segmentation을 end-to-end방식으로 네트워크를 optimize할 수 있고, local box detection과 pixel grouping의 제한에서 벗어나 pixel-level instance segmentation를 할 수 있다.
-> box free(not being restricted by anchor box location and sacales)
2. SOLO (Segmenting Object by LOcation)
1. problem formulation
SOLO의 중심 아이디어는 instance segmentation을 동시에 두가지 category-aware prediction 문제로 나누는 것임을 앞서 알아보았다. 더 자세하게 설명하자면, 이미지를 S X S의 그리드로 나누고, object의 중심이 grid cell에 떨어진다면 그 그리드 셀은 1. semantic category를 예측해야 하고, 2. 그 object instance를 segmenting 해야한다.
위에 두가지를 때어서 확인해보자.
1. Semantic category
각 grid에 대해서 SOLO는 Class의 갯수의 출력을 갖는다. 각 출력은 semantic class probabilty를 의미한다.

Category branch를 확인해보면 S X S X C의 Shape임을 볼 수 있다. 각 grid cell에는 반드시 단 하나의 instance가 속해있어야 하므로, 단 하나의 sementic category에 존재해야 한다.
2. Instance Mask
semantic category prediction와 병렬적으로, 각 positive grid cell은 각 셀에 알맞는 instance mask를 생성한다. 이미지 I를 S X S그리드로 나눈다면, 총 S^2의 predicted mask가 만들어진다. 이를 명시적으로 3D output tensor로 만들었다. (구체적으론 instance mask는 H X W X S^2의 차원) grid의 위치를 i,j라고 할 때, k번째 체널은 k = i * S + j에 해당하는 grid cell의 instance mask일 것이다. 이 처럼 semantic category와 class-agnostic mask의 one to one 관계가 생성될것이다. (즉, grid cell과 mask의 1 대 1 관계)
이 instance mask를 예측하는 직관적인 방식은 FCN과 같은 fully convolutional network을 이용하는 것이 있겠지만, convolutional operation는 공간적으로 어느정도 불변하다는 특징이 있다(spatially invariant). 이 공간적 불변성은 이미지 분류의 robustness함을 설명할 순 있지만, SOLO의 segmentation mask는 grid cell에 대한 것이고, 다른 feature channel에 대해서 분리되어야 하기 때문에 spatially variant(더 정확하게 표현하자면 position sensitive )해야 한다.
-> 이에 대해서 내 생각을 이용해서 보충 설명해보자면 FCN을 거치는 객체의 클래스 분류문제는 그저 하나의 스칼라 값이므로 위치 데이터는 상관이 없지만, Mask의 경우에는 위치 정보가 중요하기 때문에 FCN만 사용해선 안된다는 것이다. (Position sensitive 해야 한다는 것)
그렇다면 이 Spatially variant해주게 하기 위해서는 어떻게 해야할까? SOLO는 CoordConv operator를 활용하여 이를 해결하였다. CoordConv operator는 ixel의 coordinate(위치)를 normalize하고, 이를 입력 차원에 붙여 픽셀 정보와 좌표 정보를 함께 학습하는 방식이다

FPN의 각 feature level에 다음 2개의 sibiling sub-network를 붙였다. 하나는 instance category prediction을 위한 것이고 하나는 instance mask segmentation을 위함이다. mask brach에서 x,y에 대한 정보를 담는 2개의 2차원 데이터를 이어 붙임으로써 공간 정보를 incode 한다. 위 그림에서 화살표는 convolution 연산이나 interpolation을 의미한다. inference 과정에선 mask branch의 출력은 original image size로 upsample된다 // (근데 왜 2H, 2W????)
단순히 pixel의 위치를 저장하는 텐서를 concat함으로써 convolution은 자신 input의 좌표에 접근할 수 있게되므로, 이는 conventional FCN model에 spatial functionality을 추가한 것이다. 다만 CoordConv가 유일한 해결책이 아닌 하나의 예시임을 알아두자.(본 논문에서는 simplicity와 implement의 용이성을 위해서 이를 썼다고 한다.)
raw instance segmentation results는 모든 grid result 를 합쳐서 도출한다고 한다. NMS를 사용하여 마지막 instance segmentation result를 얻는다. (이 이후 더 이상의 post processing operation는 필요 없다더라 // classification 문제로 분류해서?)
2. 네트워크 아키텍처
SOLO는 convolutional backbone을 붙인다. 저자는 FPN을 사용했다고 한다. FPN은 각 level에 대해 각기 다른 크기의 고정된 channels수의 pyramid of feature maps를 생성한다. 이 맵은 prediction head(semantic category와 instance mask)에 사용된다. head의 weight들은 서로 다른 레벨에 대해 공유된다. grid number는 다른 피라미들에서 다를 수도 있다. 마지막 conv만 공유되지 않는다고 한다. (// 요건 뭔 의미지?)
이제 multiple architecture를 구상해보자. 각 아키텍처의 차이로 a)feature extraction을 위한 backbone과 b) instance segmentation result를 계산하기 위한 네트워크의 head와 c) 모델을 optimize하기 위핸 training loss로 설정하였고, 대부분의 실험은 head architectre 에 관한 것이다.
3. SOLO Learning
1. Label Assignment
S X S크기의 grid에서 (i,j)위치의 grid cell에 어떤 ground truth mask의 center region로 떨어지면 positive sample일것이고, 그렇지 않으면 negative sample일 것이다. (그니까 i,j grid에 아무 mask의 center지역이라면 positive sample이고, 그렇지 않으면 negative sample이라는거다.) object detection에서 Center sampling은 효과적인 방법이라고 한다 (27번, 12번 reference 참고해보자)
또한 mask category classification과 유사한 기술을 적용했다. ground truth mask의 mass center(c_x, c_y)와 가로(w), 세로(h)가 주어질 때, 중심 지역은 constant인 ε에 의해 컨트롤 된다. (c_x, c_y, εw, εh). 저자는 ε을 0.2로 설정했고, 결과로 하나의 ground truth mask에 대해 평균 3개의 positive samples가 나타났다고 한다. (즉, 중심 좌표와 크기를 분류하도록 함) instance category의 label뿐만 아니라, 각 positive sample에 대해 binary segmentation mask를 두었다고 한다. 각 이미지는 S^2개의 grid들에 대해 S^2개의 출력 마스크가 있다. 각 positive sample들에 해당하는 target binary mask가 명시될 것이다. 여기서 mask의 순서가 mask prediction brach에 영향을 줄 수 있지 않을까 싶을순 있지만, 결과를 보았을 때 잘 작동 되었다 카더라~
2. Loss function
optimize를 위해서 다음과 같이 Loss function을 설계하였다.

L_cate는 Semantic category classification을 위한 conventional Focal Loss(15번 ref)이고, L_mask는 mask prediction의 Loss이다.

여기서 i = [k/S]이고, J=k % S이다. N_pos는 positive sample의 수이고, p*과 m*은 각각 category와 mask target을 의미한다. 여기서 I는 indicator function으로, 뒤의 조건이 만족할 땐 1을, 만족하지 않을 땐 0을 리턴하는 연산자이다.
여기서 d_mask를 아키텍처별로 다르게 적용시켜 보았다. 그 방법으로는 Binary Cross Entropy (BCE)와 Focal Loss와 Dice Loss가 있다고 하더라~. 마지막으로 학습의 효율성과 안정성을 위해서 Dice Loss를적용시켰다고 한다. Dice Loss는 다음과 같이 정의되었다.

여기서 D는 dice coefficient로, 다음과 같이 정의되었다.

여기서 p_x,y와 q_x,y는 예측 soft mask인 p와 ground truth mask인 q의 좌표 (x,y)에 위치한 픽셀의 값이다.
4. Inference
SOLO의 inference는 매우 직설적이다. input image에 대해서, Backbone 네트워크인 FPN을 통과시키고, category socre인 p_i,j와 그에 해당하는 mask인 m_k를 얻는다(여기서 k=i*S + j). 가장 먼저 confidence threshold를 0.1로 설정하고 낮은 confidence를 갖는 mask를 다 필터링 한다. 그리고 가장 높은 score를 갖는 500개의 mask를 입력으로 NMS 연산을 시행한다. NMS의 출력의 threshold는 0.5로 설정하여 예측 soft mask를 binary mask로 변환한다.
1. Maskness
각 예측 mask에 대해 maskness를 계산한다. 여기서 masknesas란, mask prediction의 confidence로 다음과 같이 계산한다.
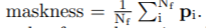
여기서 N_f는 예측한 soft mask p의 foreground pixel(그 중에서도 threshold가 0.5보다 큰 값을 지닌 픽셀의) 갯수이다. 각 prediction은 최종적으로 maskness와 곱해져 최종 confidence score를 도출한다.
4. 결과 비교의 몇가지 눈에 띄는 점
1. Loss의 결과 비교
focal loss가 ordinary binary cross entropy loss보다 좋았다 ->instance mask의 대부분의 픽셀이 background에 있고, focal loss는 잘 분류된 샘플의 loss의 감소로 인한 sample imbalance 문제를 완화하기 위해 디자인 되었기 때문이다.
하지만 Dice Loss가 하이퍼 파라미터 조정을 일일히 해줄 필요없이도 최고의 결과를 나타내었는데, Dice Loss는 픽셀을 전체 객체로 보고, 백그라운드 픽셀과 포그라운드 픽셀의 차이의 올바른 밸런스를 자동으로 찾아낼 수 있기 때문이다. 다른 알고리즘이 문제에 따라, 하이퍼 파라미터를 잘 조정한다면 더 좋아질 여지는 있지만 포인트는 Dice Loss가 훨씬 더 안정적이고, heuristic을 이용할 필요 없이도 좋은 결과를 내는 경향이 있다는 것이다.
2. Alignment in the category branch
category prediction branch에서 H X W크기의 spatial size를 갖는 convolutional feature를 S X S로 낮춰야 한다. (gird cell 별로 prediction을 하기 때문에, channel의 크기를 맞춰주는건 나중에 하므로 우선 넘어가자) 이 과정에서 interpolation, adaptive-pool, region-grid-interpolation을 변인으로 두었는데 그다지 큰 차이는 보이지 않았다고 한다.
3. 다른 head depth
SOLO에서 instance segmentation은 pixel-to-pixel task로 구성되어 있고, mask의 spatial layout를 FCN(Fully Convolutional Network)을 사용함으로써 이용하였다. 서로 다른 head depth에 대해서 실험을 해보았는데, dpeht가 7전까지는 AP가 커지고, 그 이상으로 커질 때는 변화가 안정화 된다고 한다.(거의 없다 카더라~)
4. 더 작은 모델?
더 작은 input resolution을 입력으로 하여 더 작은 모델을 만들었다고 한다.
5. Decoupled SOLO
S^2의 채널을 갖기에는 너무 큰 차원이다 -> X를 위한 H X W X S와 Y를 위한 H X W X S로 나누어, forward하고, 그 결과를 곱하여 기존과 유사한 결과를 나타내도록 하였다. 이것의 기본 아이디어는 셀 (i,j)의 probabilty는 horizontal과 vertical location categories가 독립적이라면 i번째 row의 확률과 j번째 컬럼 확률의 joint probabilty라는 것이다. 실험 결과는 유사하거나 오히려 Decoupled SOLO가 더 좋은 결과를 낼 때도 있다고 한다.

이를 이용하면 training, testing과정에서 GPU 메모리 사용량이 현저하게 줄어들었다고 한다.
'ML' 카테고리의 다른 글
| SIFT (Scale-Invariant-Feature TRansform)를 활용한 이미지 특징 추출 및 매칭 알고리즘 (1) | 2021.07.20 |
|---|---|
| SOLOv2 논문 리뷰 (0) | 2021.07.18 |
| CS231n lecture 12 : Visualizing and Understanding (0) | 2021.07.12 |
| CS231n Lecture 11 : Detection and Segmentation (0) | 2021.07.12 |
| Recurrent Neural Network (RNN) (0) | 2021.07.10 |