
이전까지 우리는 데이터의 분포를 확인하였고, Null값을 채워주었으며 model을 정의하고 상관관계가 높은 feature들을 삭제해주었다.
이제 데이터를 정규화 / outliers를 제거하는 과정을 거쳐보자.
우선 각 데이터의 분포를 확인해보자.

1 398
0 93
Name: Gender, dtype: int64
----------------------
1 315
0 176
Name: Married, dtype: int64
----------------------
0 292
2 85
1 78
3 36
Name: Dependents, dtype: int64
----------------------
0 382
1 109
Name: Education, dtype: int64
----------------------
0 428
1 63
Name: Self_Employed, dtype: int64
----------------------
1 421 0 70
Name: Credit_History, dtype: int64
----------------------
1 179
2 170
0 142
Name: Property_Area, dtype: int64
----------------------
0.000000 222
0.414374 1
0.912892 1
1.258120 1
0.504299 1
... 0.330420 1
2.332134 1
0.844471 1
0.564642 1
0.824769 1
Name: new_col, Length: 270, dtype: int64
----------------------
43200.0 18
39600.0 13
36000.0 11
57600.0 11
46080.0 9
.. 3000.0 1
12000.0 1
9072.0 1
25920.0 1
7560.0 1
Name: new_col_2, Length: 211, dtype: int64
----------------------
우리가 만든 new_col_2의 분포를 plot해보자.

데이터야 약간 치우침을 확인할 수 있다. 그렇기 때문에 각 값의 log를 취해줌으로써 최대한 정규분포에 가까워 지도록 정규화를 진행해주자.

또한 new_col을 확인해 보았을 때, 0의 갯수가 압도적으로 많고, 나머지 값들은 산포되어 있음을 확인할 수 있다.
그렇기 때문에 이 float형을 bool의 형태로 변형하여 데이터의 분포를 균일하게 만들자.
분포가 어느정도 균일하게 됨을 확인할 수 있따.
이젠 이 값들에 이상값(outliers)을 제거하는 과정을 거쳐야 한다.
outliers는 그 갯수가 많지 않을지라도 피팅과정에서 큰 악 영향을 미치기 때문에 제거해주는 과정이 필요한 것이다.
이상치 값이 이상치일까?


그래프에서 확인하다 싶이, outliers들이 꽤나 많이 존재함을 확인할 수 있다. 우리는 모델에 악영향을 주는 이런 outliers들을 삭제해 주어야하는것이다. 그렇다면 outliers들은 어떻게 판별해야 할까?
일반적으로 데이터를 크기순으로 정렬하였을 때, 분포도를 기준으로 1/4씩 나누고 1/4~3/4의 값이 정상적인 분포라고 생각하고 이 부분을 IQR(Inter Quanatile Range)라고 한다. 이 부분 외에도 (IQR의 범위 * threshold) 만큼을 양옆으로 확장된 범위까지 정상된 범위라고 생각하고 그 외에는 outliers라고 판단하고 삭제한다.


outliers를 정의해두고, 정의된 outliers를 drop한 후 boxplot을 하였다. 정상적으로 값이 분포됨을 확인할 수 있다.
이렇게 new_col_2에 대한 데이터 처리가 끝난게 되었다.
이제 new_col에 대해 데이터를 처리해보자. 위에서 new_col의 분포를 확인함으로써 우리는 0의 값이 지나치게 많고, 다른 이산적인 값의 갯수는 매우 적음을 확인할 수 있었다.
때문에 0이외의 양수를 1로써 설정해주고 데이터를 다시 분포시켜보자.
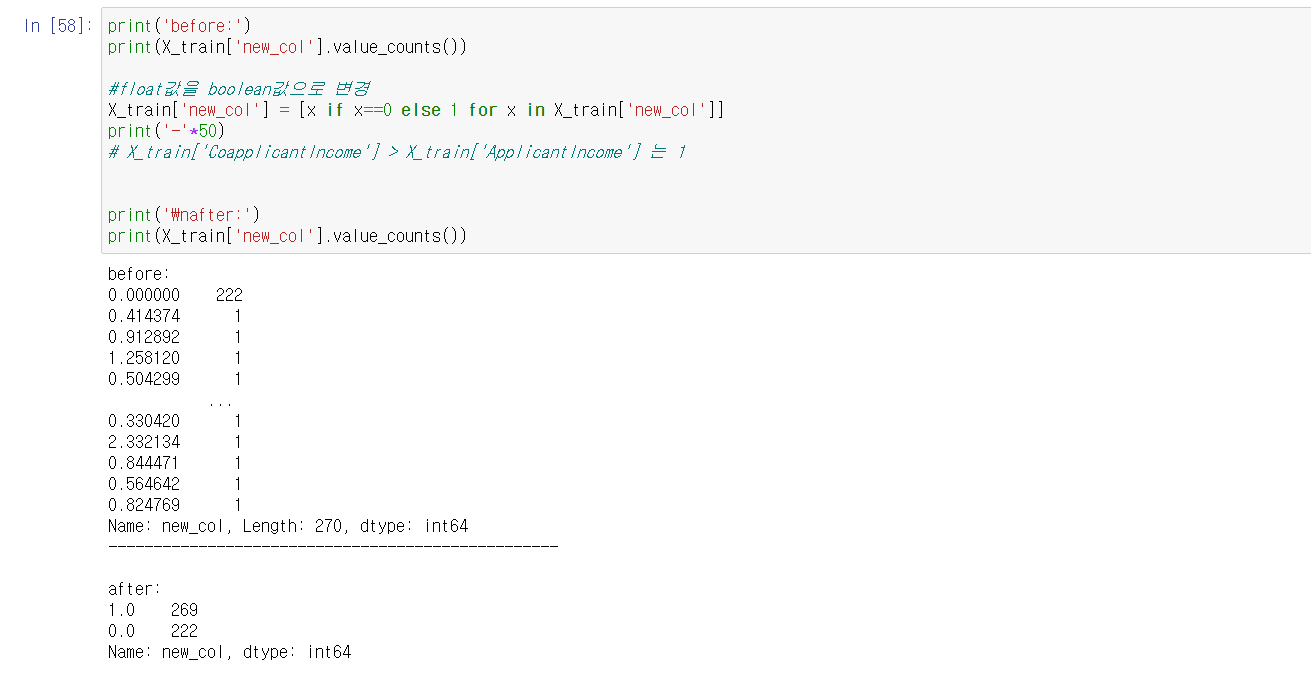
위와 같이 분포가 적당히 잘 되었음을 확인해 볼 수 있다.
마지막으로 feature selection을 통해서 response feature과 상관관계가 0에 가까운 self_employed를 제거해주고 초기 모델과 최종 모델을 비교해보자.

결과를 확인해보니 초기 모델과 정확도가 그렇게 달라지지 않음을 볼 수 있다.
사실 포스팅 과정에서 생략되었는데 feature선택, 데이터 처리 모든 과정에서 데이터를 학습시켜보았고, 각 모델을 비교해 보았으나, 결과는 하나같이 똑같았다.
Kaggle의 커멘트를 바탕으로 확인해보니, 데이터(record)의 갯수가 614개로 너무 적고, 라이브러리가 우리가 진행한 부분을 자동으로 처리해주는 부분도 존재하기 때문인 것으로 추측된다.
수치적으로는 의미가 없었지만 개인적으로는 모델을 정의하고, 정확도를 확인하를 함수를 정의하고 feature의 차원을 조절하고 데이터를 처리해주는 과정들에서 많이 배웠던 것 같다.
다음엔 더 많은 데이터로 각 스텝별로 유의미한 결과를 낼 수 있으면 좋겠다!
'ML' 카테고리의 다른 글
| DQN 논문 해석, 분석 (0) | 2021.04.02 |
|---|---|
| DQN 2013 vs DQN 2015 방식 (0) | 2021.03.31 |
| 프로젝트 1 : 대출 가능 여부 예측 문제 / 스텝 4 : feature selection (0) | 2021.03.24 |
| 프로젝트 1 : 대출 가능 여부 예측 문제 / 스텝 3 : 모델 정의하기 (0) | 2021.03.21 |
| 프로젝트 1 : 대출 가능 여부 예측 문제 / 스텝 2 : Null 데이터 채우기 (0) | 2021.03.21 |