
0. AlexNet
가장 처음 LeNet-5라는 CNN 아키텍처가 있었다. 하지만 하드웨어의 한계로 유의미한 성과를 내지 못했었는데, 하드웨어가 발달함에 따라 이 아키텍처를 더 키운 AlexNet이 2012년에 발표되었다. 파라미터의 갯수는 필터의 크기 x 필터의 갯수이므로 첫번째 레이어만 약 3만 5천개((11*11*3)*96)의 파라미터가 들어갈 만큼 AlexNet은 LeNet-5에 비해 커졌음을 확인할 수 있다. 다음은 AlexNet의 구조도이다.

당시의 하드웨어적 한계(그래픽 카드의 메모리가 3GB 였음)로 인하여 레이어가 같은 레이어더라도 반씩 나누어 연산을 하였으며, GPU간의 통신이 느리기 때문에 1,2,4,5번째 CONV는 같은 GPU에 속한 feature map에 대하여 전파하였으며, 3번째 CONV, 6,7,8번째 Fully Connected layer에서 GPU간의 통신을 이용하여 모든 입력에 대한 연산을 했다.
AlexNet 이후에 하이퍼 파라미터를 개선한 ZFNet이 등장하였고, 레이어의 더 깊게 쌓은 VGG, GoogleNet등이 등장하였다. 두가지를 나누어서 확인해보자
1. VGG
레이어를 더 깊게 쌓기 위해서는 파라미터의 수를 줄이는 것이 필수적이었기 때문에 작은 필터를 갖는 레이어들을 더 깊게 쌓는 방식을 채택하였다. 이는 파라미터 크기에 꽤 영향을 미쳤는데, 같은 크기의 receptive field(필터가 한번에 볼 수 있는 입력의 공간적 크기)라도, 큰 하나의 필터보다는 작은 필터를 여러 번 쌓는것이 더 적은 파라미터를 필요로 했기 때문이다. 예시로는 3x3크기의 필터를 갖는 3개의 레이어와 7x7크기의 필터를 갖는 1개의 레이어를 비교하였는데, receptive field가 7x7으로 동일했음에도, 파라미터의 수는 27 * C^2개와 49 * C^2로 전자가 더 효율적이었다.
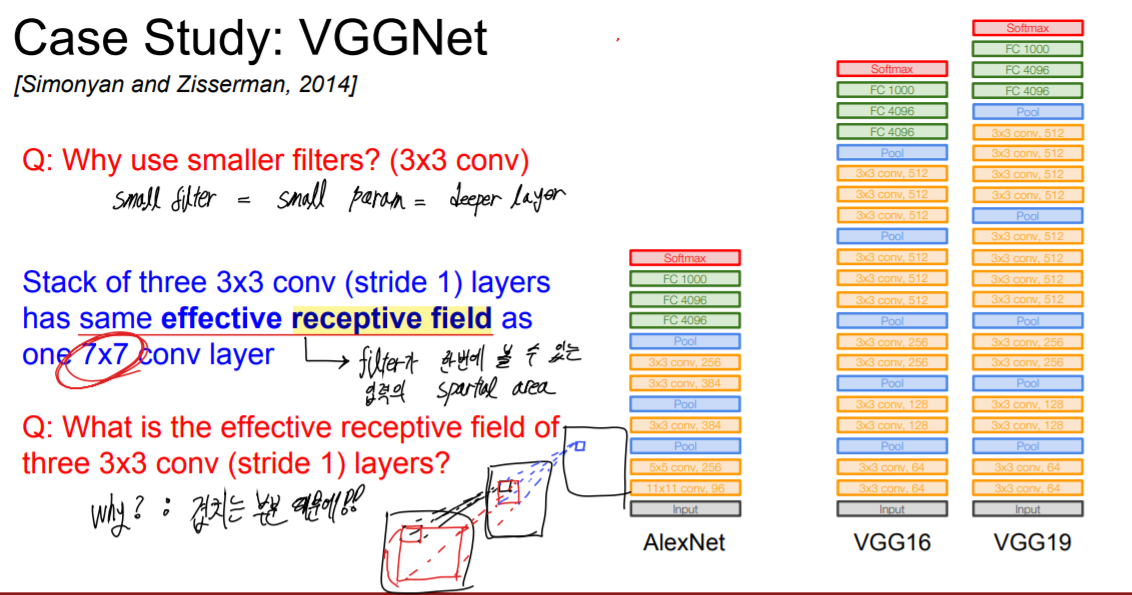
다음은 레이어의 구조 및 레이어 별 파라미터의 크기이다.

대부분의 메모리가 초기 CONV에 몰려있고(차원이 크기 때문에), 대부분의 파라미터들이 마지막 Fully Connected layer에 몰려있음을 확인할 수 있다. 그렇기 때문에 FC 레이어의 갯수를 줄여 CONV를 더 깊게 쌓기도 하였다더라. 비록 2014년에 Accuracy는 GoogleNet에 밀려 2등을 하게 되었지만 이미지 상에서 예측 클래스의 위치를 판별하는 localization은 1등하였을 만큼 좋은 모델이다.
2. GoogleNet
이 방식은 하나의 레이어를 깊게 쌓기 보다는 서로 다른 크기의 작은 필터를 병렬적으로 쌓고, 연산 결과를 하나로 합치는 레이어를 이용하여 만든 하나의 모듈(Inception module)을 쌓는 형태이다. 여기서 Inception module이란 좋은 로컬 네트워크 topology(네트워크 안의 네트워크)를 의미한다.

더 레이어를 깊게 쌓기 위해서 FC를 없앴고, 효율적인 Inception module를 설정하였으며, 파라미터의 수가 500만개 (VGG vs GoogleNet = 138 : 5)밖에 안되면서도 Accuracy가 2014년에 1등을 할 정도로 효율적인 모델이었다.
이 모델을 이해하기 위해서는 Inception module을 이해해야 하는데, 하나의 레이어에 다중 receptive field를 갖는 필터와 풀링 연산을 이용하는 모듈이다. 이런 필터들의 연산을 나중에 이어 붙여 다음 레이어로 전파하는 방식이다. 서로 다른 필터의 크기를 수용하기 위해서 필터 별 stride, zero padding 들을 이용하여 각 필터별 출력 크기를 통합해 주었다.
또한 기존 방식을 그대로 차용할 때 이 모듈은 너무나도 많은 연산을 요구하였다. 다음 예시를 보자.
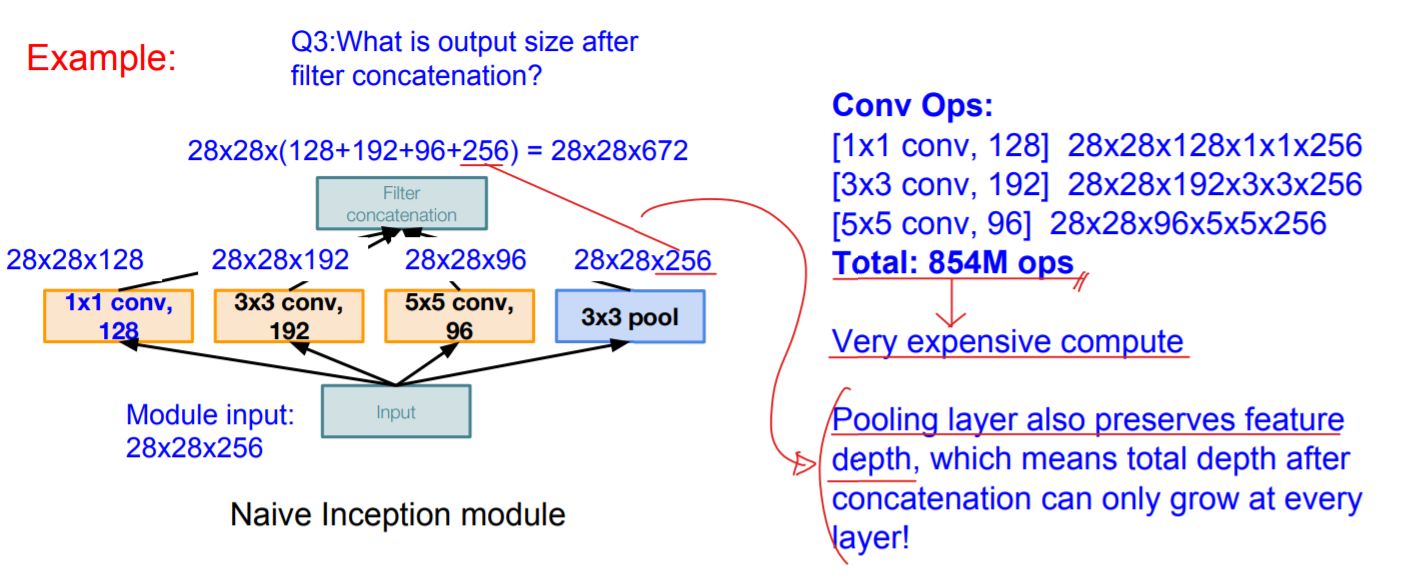
pooling은 입력 차원을 그대로 전달하므로, inception module을 거칠 때 마다 차원은 깊어질 수 밖에 없고, 그렇게 되면 모듈을 깊게 쌓을 수 없게 된다. 이와 같이, 그대로 Convolutional 연산을 하기에는 무리가 있기 때문에 bottleneck레이어를 이용하여 feature의 깊이를 낮춰주어야만 했다.
bottleneck이란, 공간적 차원을 유지하면서 깊이를 줄이는 방식으로, 내적을 이용한 feature maps의 결합이라는 의미를 갖는다.

물론 정보 손실이 존재하지만, 낭비가 있는 input features를 선형결합한다는 관점으로 바라볼 수 있다. 이를 활용하여 개선된 inception module과 연산수를 비교해보자.

GoogleNet에는inception module part이외에도 일반 ConvNet과 같이 Conv-Pool을 반복하는 Stem network와, classifier part가 존재한다. 특이하게도 GoogleNet은 최종 분류기 뿐만 아니라, 보조 분류기도 존재한다. 레이어가 깊어질 수록 얕은 레이어의 gradient의 변화가 희미해지므로, 중간단에 보조 분류기를 넣어 중간 레이어의 학습을 윤활하게 하는것이다.

3. ResNet
이와 같이 네트워크의 깊이를 더 깊게 하는 것의 효과가 입증되면서 깊이를 극한으로 깊게 하는 네트워크들이 나타났다. 그것이 2015년 ImageNet에서 1등을 수상한 ResNet이다.
이 RestNet은 기존 GoogleNet의 22개의 레이어 갯수와 비교했을때 152개의 레이어라는 급격한 차이를 보여주었는데, 성능 측면에서 오차율도 절반정도로 줄어들 정도로 효과적이었다.
이 모델은 "모델이 깊어지면 깊어질수록 더 좋은 결과를 낼 것이다"라는 아이디어에서 부터 출발했다. 하지만 실제 비교했을 때는 그렇지 않았다.
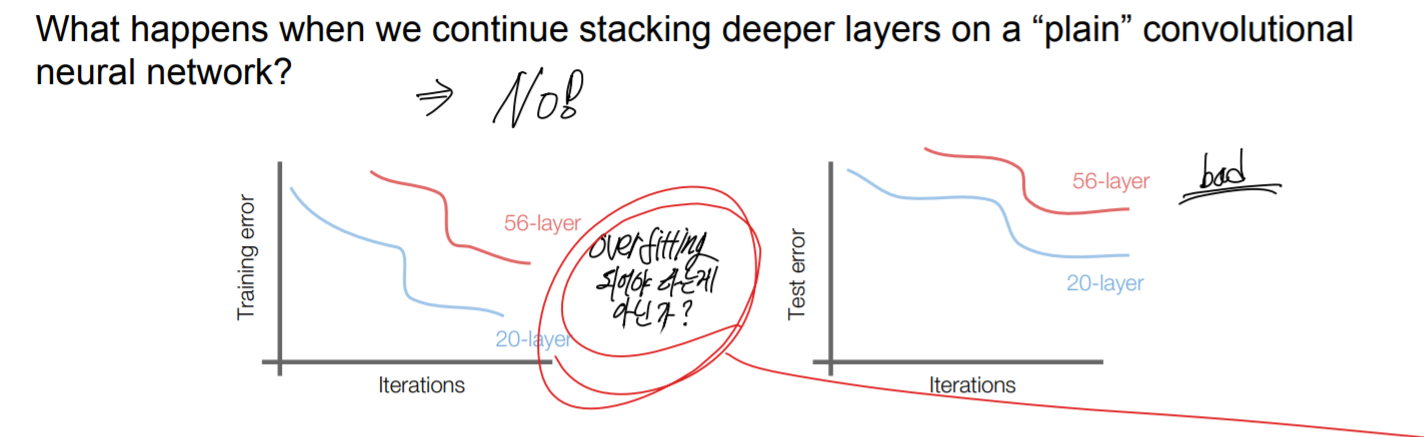
기존에 layer가 깊으면 overfitting되어 성능이 떨어진다고 여겨졌으나, 실제로 비교해본 결과 training time에서 overfitting이 되지 않음을 확인하였다, 그렇기 때문에 깊어질수록 떨어지는 성능은 overfitting이 아닌 깊어질 수록 optimize하기 어려워 진다는 가설을 바탕으로 어떻게 깊은 네트워크를 효과적으로 optimize할지 생각하게 되었다.
얕은 모델을 학습하고, 그 결과를 깊은 네트워크의 아랫단에 넣고, 모든 뉴런이 입력을 그대로 출력으로 보내는 깊은 모델을 만든다면 이 성능은 얕은 모델과 같아야 할 것이다. 이 아이디어에 따라 h(x)를 예측하는 것이 아닌 h(x) = f(x) + x 라고 생각하고, 변화량인 f(x)를 학습하도록 변경하였다. 즉, 기존에 결과를 예측하는 학습이 아닌 변화량에 대한 학습으로 바꾼 것이다.
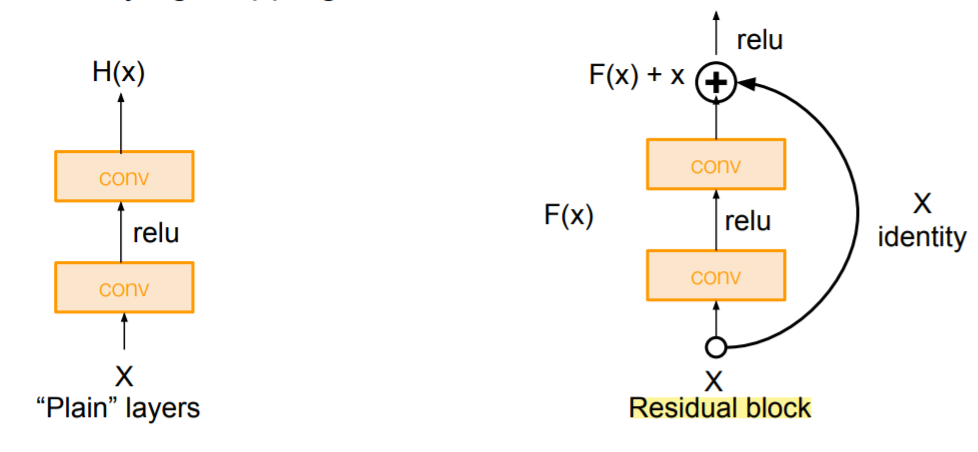
이렇게 했더니 학습이 더 잘 되었다고 한다. 그 이유는 입증된 바는 없다고 하더라~ 이에 대해 이 방식은 효과가 없다 라고 주장하는 사람도 많고, 아직 연구가 되는 부분이라고 한다~ 어쨋든 레이어가 깊다는게 중요하다.
이렇게 생긴 레이어를 3x3크기의 매우 작은 필터로 구성하여 한 레이어의 파라미터 갯수를 매우 적게 하여 깊게 레이어를 쌓을 수 있게 되었다.

그러다가 규칙적으로 stride를 2로 하여 입력의 차원을 2배로 줄이고, 그 대신 depth의 크기를 2배로 하는 구조를 설계하였다. 거기다가 더 깊은 네트워크를 위해서 bottleneck도 적용하였다.

// 근데 이거 입력과 결과의 차원이 같잖아.... 이 이후에 파라미터 갯수에 대한 영향은 없을것같은데.... 그럼 그냥 feature map을 내적해서 하나의 값으로 나타낼라고 하는 그 뿐인건가?
4. 모델 비교


5. ETC
1. Network in Network (NiN)
Mlpconv layer과 같이 ConvNet이랑 MLP등을 복합적으로 써서 더 추상적인 feature를 계산할 수 있다. 이 아이디어가 적용된 것이 GoogleNet과 ResNet의 bottlenect레이어이다.

// 실제 효과가 궁금하다.
2. Identity Mappings in Deep Residual Networks
더 직접적인 경로를 만들어 backpropagation를 윤활하게 하는 방식이다. 더 좋은 성능을 나타낸다고 한다.
기존에 단순히 아래와 같이 블록이 형성되었다면
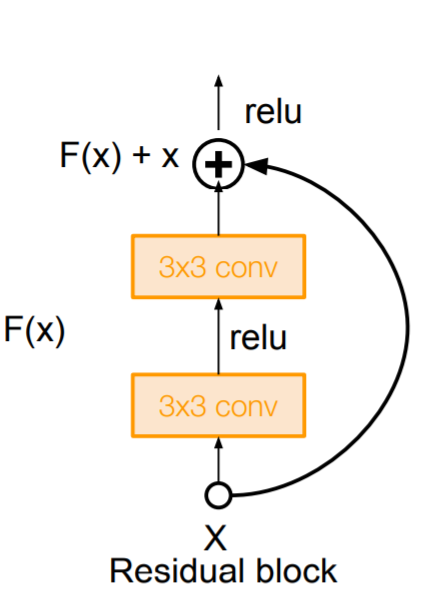
하나의 블록이 더 직접적인 경로를 갖게 형성하라는 것이다.
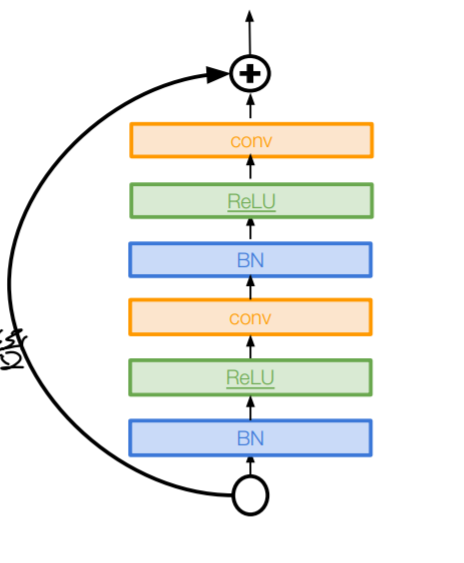
3. Wide Residual Network
ResNet에서 Depth가 아닌, Width를 넓히자는 아이디어. GPU가 병렬적인 계산에 특화되어 있으니, 이렇게 병렬적으로 배치하면 계산의 효율성이 올라가므로, 효율적이라고 한다.
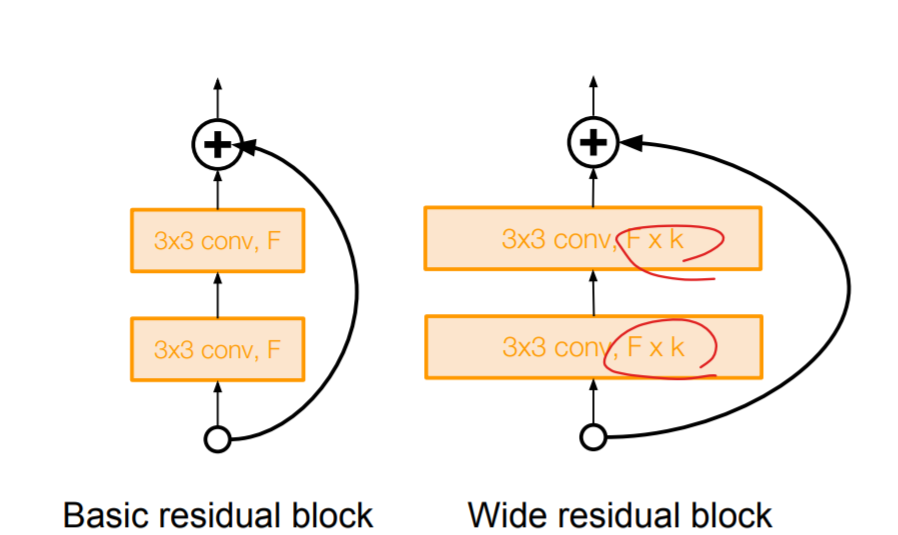
4. Aggregated Residual Transformations for Deep Neural Networks (ResNeXt)
Wid Residual Network에서 Width를 넓히는 대신 크기를 유지시키고 병렬적으로 block을 이어붙이자는 것이다. 이는 Inception module과 비슷하다.
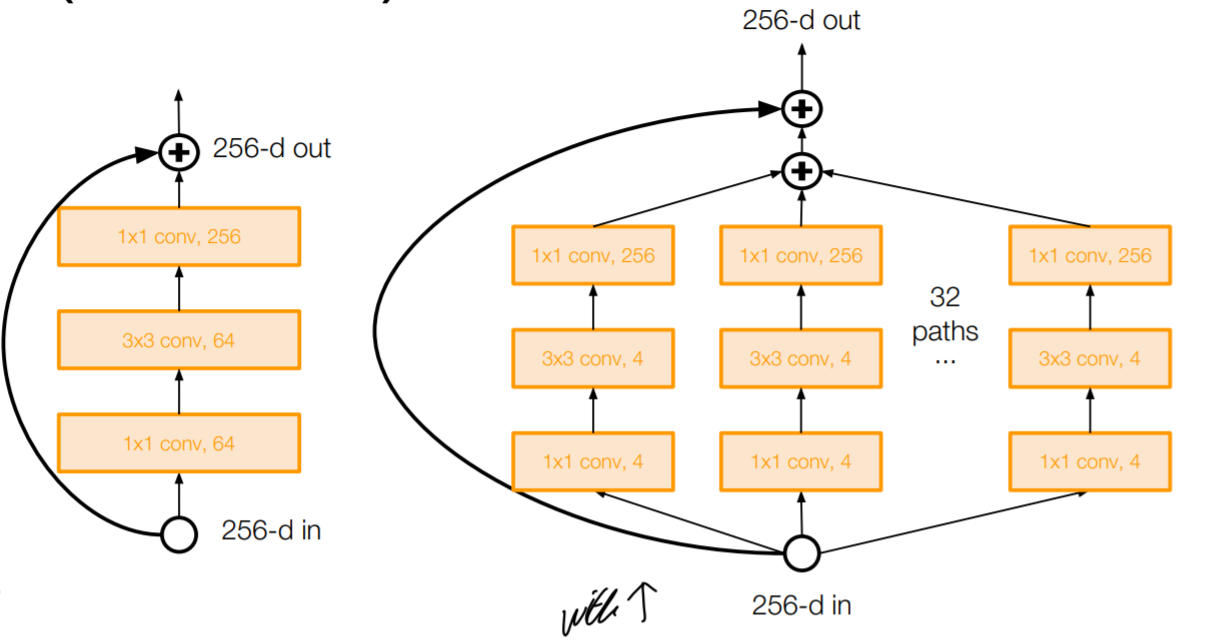
5. ETC


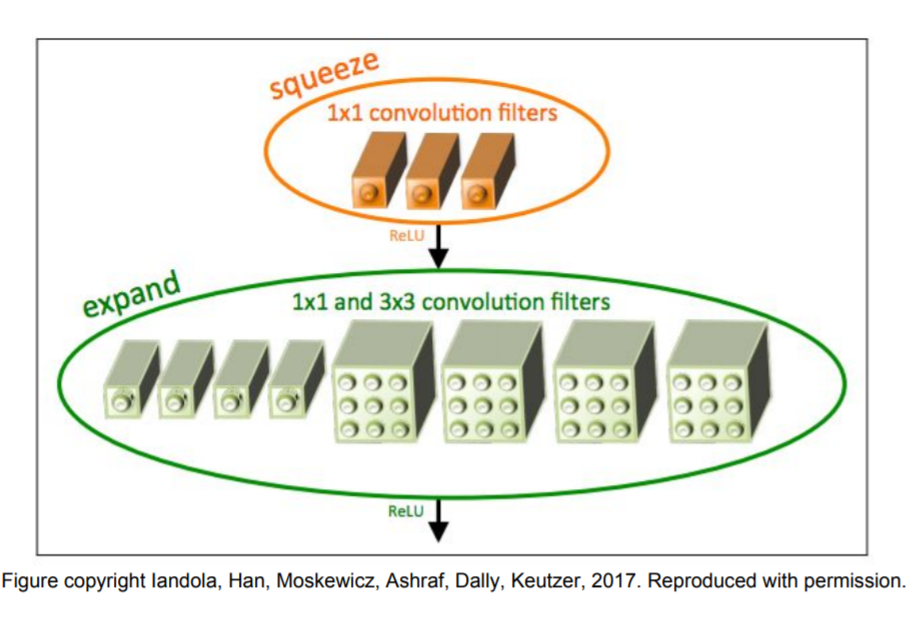
SqueezNet은 좀 흥미로웠다. AlexNet의 정확도를 가지면서 그보다 510배나 적은 파라미터로 모델을 구성할 수 있다고 한다.
// SqeezNet 조금 더 알아보기
'ML' 카테고리의 다른 글
| CS231n Lecture 11 : Detection and Segmentation (0) | 2021.07.12 |
|---|---|
| Recurrent Neural Network (RNN) (0) | 2021.07.10 |
| 인공지능 Learning rate, Regularization, Weight update, Transfer Learning (0) | 2021.07.05 |
| 다양한 Gradient descent optimization (0) | 2021.07.05 |
| 인공 신경망 학습 (0) | 2021.07.05 |