
Building a Powerful DQN in TensorFlow 2.0 (explanation & tutorial)
And scoring 350+ by implementing extensions such as double dueling DQN and prioritized experience replay
medium.com
이걸 참조하여 실습을 진행해보자.
1. Frame Processor
스크린에 표현된 픽셀데이터를 이용해서 학습할것이다.
아타리의 스크린 데이터는 210x160 RGB으로 각 캡쳐 당 표현해야할 데이터의 수는 210x160x3=100800로 너무 과다하게 많다.
이를 Frame Processor를 통해 줄여줄 것이다. 색을 단일색(여기선 gray)으로 변경하고 84x84로 크기를 조절한다.
이렇게 된다면 100,800에서 7,056로 7%의 데이터 크기를 줄일 수 있는 것이다.
이를 위해서는 다음의 라이브러리들이 필요하다.
- OpenCV(cv2) : 색 변경과 크기변경을 포함한 컴퓨터 비젼 라이브러리.
pip install opencv-python
import cv2
import numpy as np
# This function can resize to any shape, but was built to resize to 84x84
def process_frame(frame, shape=(84, 84)):
"""Preprocesses a 210x160x3 frame to 84x84x1 grayscale
Arguments:
frame: The frame to process. Must have values ranging from 0-255
Returns:
The processed frame
"""
# cv2를 통한 데이터 감소를 이용하기 위해선 반드시 데이터 형을 np.uint8로 만들어야함
frame = frame.astype(np.uint8)
# RGB -> GRAY로 색 변경
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
# 프레임을 crop한다 ([0~34, 160 ~ 160+34] 범위 삭제 )
frame = frame[34:34+160, :160]
# 크기를 인자로 전달된 shape로 리사이징 한다
frame = cv2.resize(frame, shape, interpolation=cv2.INTER_NEAREST)
# reshape한다
frame = frame.reshape((*shape, 1))
return frame이 과정을 거치면 데이터는 다음과 같이 변경될 것이다.

색, 크기가 모두 변경되는것을 확인할 수 있다.
2. Q-network Architecture
네트워크의 결과는 상태 s에 대해 액션 a를 취할 때 기댓값 Q-Values, Q(s,a)로써 표현되고, 이 값이 높을수록 더 높은 보상을 받을것으로 예상된다.
이 네트워크는 convolutional layer들과 fully-connected layer과 가능한 액션에 대한 fully connected layer로 구성되어 있을것이다. 다음은 네트워크의 청사진이다.
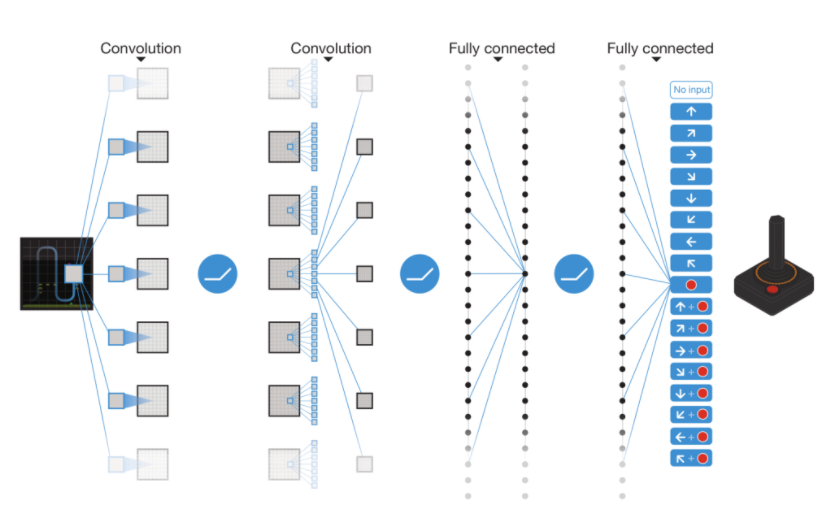
결국 visual data -> network -> Q(s,a); next step = max_step(Q(s,a))
이와 같이 진행될 것이다.
여기서 몇가지를 짚고 넘어가자.
Convolutional(CONV) layer는 무엇일까?
Convolutional layer (ConvNet, CNN)
1. Convolutional layer (ConvNet, CNN)란? dense(fully connected) layer로만 이루어진 뉴럴넷, MLP의 한계를 극복한 layer MLP의 한계? MLP를 통해 효과적으로 비선형 함수를 모사할 수 있었고, 이 단순한 비선..
do-my-best.tistory.com
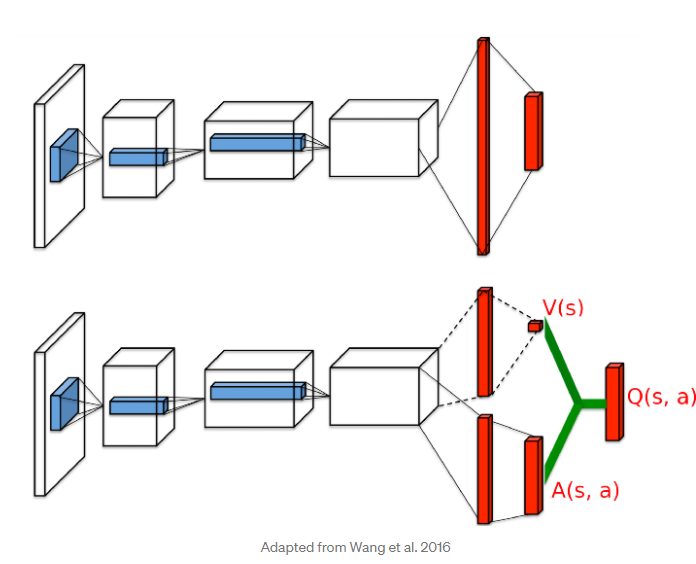
네트워크 아키텍처는 다음 논문을 참고할 것이다 Wang et al. 2016
이 아키텍쳐는 상태에 따른 가치를 추측하는 2가지 분리된 stream이 존재하는데 하나는 상태 s에 따른 가치를 추측하는 V(s) (즉, 얼마나 좋은 상태인지를 수치화하는 stream)이고 하나는 상태s와 그 상태에서 가능한 행동 a을 수행함에 따른 이익을 표현하는 A(s,a) (즉, 얼마나 이 행동이 다른 것보다 얼마나 더 나은지를 수치화 하는 stream)이 존재할 것이다.
볼이 바로 접근하는 다음 사진을 예시로 확인해보자
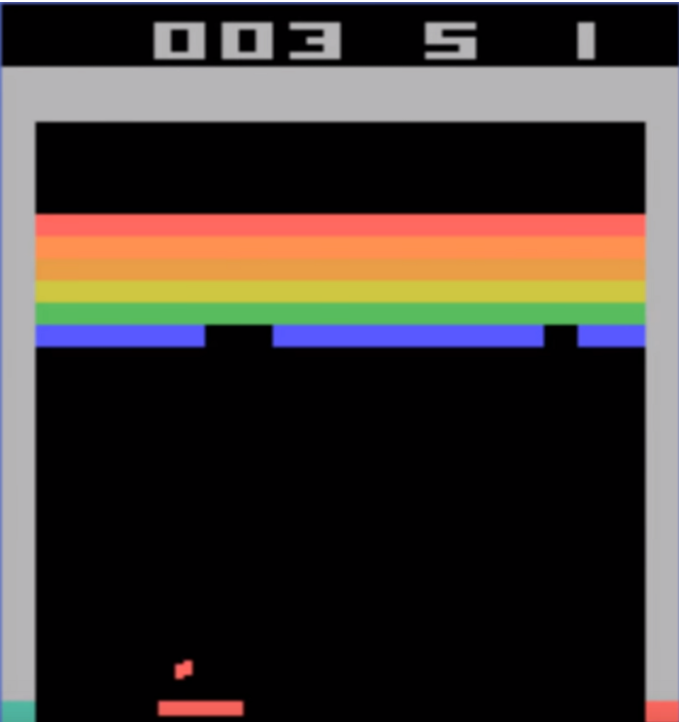
다음 예시를 한번 생각해보자. 이 상황에서 왼쪽으로 움직이는 것이 더 높은 가치를 가질것이고 오른쪽으로 움직이는 것이 더 낮은 가치를 갖게 될 것이다.
이와 같이 V(s)와 A(s,a)를 나눔으로써 네트워크는 직관적으로 어떤 상태 s가 가치가 높을 것인지(V(s))를 각 상태 s에서 행동 a의 영향에 대해 배우지 않아도 알 수 있기 때문에 training의 속도를 높여준다.
지금까지 살펴본 모델 내용들을 코드로써 구현해보자
import tensorflow as tf
from tensorflow.keras.initializers import VarianceScaling
from tensorflow.keras.layers import (Add, Conv2D, Dense, Flatten, Input,
Lambda, Subtract)
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
def build_q_network(n_actions, learning_rate=0.00001, input_shape=(84, 84), history_length=4):
"""Builds a dueling DQN as a Keras model
Arguments:
n_actions: Number of possible action the agent can take
learning_rate: Learning rate
input_shape: Shape of the preprocessed frame the model sees
history_length: Number of historical frames the agent can see
Returns:
A compiled Keras model
"""
# 파라미터를 통한 model_input 정의
model_input = Input(shape=(input_shape[0], input_shape[1], history_length))
x = Lambda(lambda layer: layer / 255)(model_input) # normalize by 255
# convert 2d
x = Conv2D(32, (8, 8), strides=4, kernel_initializer=VarianceScaling(scale=2.), activation='relu', use_bias=False)(x)
x = Conv2D(64, (4, 4), strides=2, kernel_initializer=VarianceScaling(scale=2.), activation='relu', use_bias=False)(x)
x = Conv2D(64, (3, 3), strides=1, kernel_initializer=VarianceScaling(scale=2.), activation='relu', use_bias=False)(x)
x = Conv2D(1024, (7, 7), strides=1, kernel_initializer=VarianceScaling(scale=2.), activation='relu', use_bias=False)(x)
# V(s)와 A(s,a)로 stream 분리
val_stream, adv_stream = Lambda(lambda w: tf.split(w, 2, 3))(x) # custom splitting layer
# V(s) 정의
val_stream = Flatten()(val_stream)
val = Dense(1, kernel_initializer=VarianceScaling(scale=2.))(val_stream)
# A(s,a) 정의
adv_stream = Flatten()(adv_stream)
adv = Dense(n_actions, kernel_initializer=VarianceScaling(scale=2.))(adv_stream)
# reduce mean를 수행하는 custom layer 정의
reduce_mean = Lambda(lambda w: tf.reduce_mean(w, axis=1, keepdims=True))
# Q-Values로 V(s)와 A(s,a)를 합침
q_vals = Add()([val, Subtract()([adv, reduce_mean(adv)])])
# model빌드
model = Model(model_input, q_vals)
model.compile(Adam(learning_rate), loss=tf.keras.losses.Huber())
return model
지금까지 프레임을 전처리하고, 네트워크를 정의해보았다.
다음에는 환경을 정의하고, agent를 정의해보겠다.
'ML' 카테고리의 다른 글
| DQN의 입력 (0) | 2021.04.07 |
|---|---|
| TensoFlow를 활용한 DQN 실습 Breakout 적용 - 2 (0) | 2021.04.03 |
| Convolutional layer (ConvNet, CNN) (0) | 2021.04.02 |
| DQN 논문 해석, 분석 (0) | 2021.04.02 |
| DQN 2013 vs DQN 2015 방식 (0) | 2021.03.31 |