
3. Game Wrapper
Game Wrapper 객체의 의미? 역할?
Game enviroment, emulator의 역할을 할 것이다.
이 Game Wrapper는 두 가지 중요한 것을 제공할 것이다
1. enviroment 그 자체
2. agent에게 학습될 상태 s
breakout의 예시로 들자면, 볼과 블락 등 상태 s의 연속과 행동a를 이해하는 것이 매우 중요하다.
그렇기 때문에 다중 상태 (multiple states)를 Q-network에 학습시켜야 한다.
이 코드에서는 4개의 과거 프레임을 Q-network에 학습 시켜볼 것이다.

각 프레임에 대해서 프레임 차를 둬야지 더 충분한 움직임을 확인할 수 있을것이다. 따라서 각 프레임 당 4개의 프레임을 스킵함으로써 계산량을 줄이고 더 인간같은 리액션을 만들 수 있을것이다.
이는 다행히도 BreakoutDeterministic-v4에 구현되어 있고, 이는 자동적으로 위의 행동을 취해줄 것이다
코드를 확인해 보기 전에 다음 함수들에 대해서 알고가자.
1. reset : 환경을 초기화 시키고 초기 state를 설정한다.
2. step(a) : 주어진 환경 s와 행동 a에 대해서 내부 환경을 갱신한다. 이는 오래된 frame을 삭제하고 새로운 프레임을 붙임으로써 구현된다. 그리고 이는 환경 s에 대한 정보를 리턴할 것이다.
import random
import gym
import numpy as np
# This is the process_frame function we implemented earlier
from process_frame import process_frame
class GameWrapper:
"""Wrapper for the environment provided by Gym"""
# 생성자, gym과 인자를 통한 객체 생성
def __init__(self, env_name, no_op_steps=10, history_length=4):
self.env = gym.make(env_name)
self.no_op_steps = no_op_steps
self.history_length = 4
self.state = None
self.last_lives = 0
def reset(self, evaluation=False):
"""Resets the environment : 리셋, 과거 env를 리셋한다.
Arguments:
evaluation: agent가 평가될 때 True로 설정, no-op steps의 임의의 수를 설정한다
"""
self.frame = self.env.reset()
self.last_lives = 0
# If evaluating, take a random number of no-op steps. This adds an element of randomness, so that the each evaluation is slightly different.
# 임의의 no-op steps의 번호를 받는다. 이는 원소에 random함을 추가하여 각 평가가 조금씩 다르게 만들어 준다
if evaluation:
for _ in range(random.randint(0, self.no_op_steps)):
self.env.step(1)
# 첫 상태에서 첫 frame을 4회 쌓는다
self.state = np.repeat(process_frame(self.frame), self.history_length, axis=2)
def step(self, action, render_mode=None):
"""Performs an action and observes the result : 행동을 취하고 결과를 확인한다.
Arguments:
action: agent가 선택한 행동의 번호
render_mode: 'None'이라면 아무것도 render하지 않는다. 'human'이면 새 스크린에 render하고, 'rgb_array'라면 rgb 값의 np.array를 리턴한다.
Returns:
processed_frame: 행동의 결과로 연산된 새 프레임
reward: 행동으로 인한 보상
terminal: game이 종료되었는지를 표시하는 값
life_lost: life가 깎였는지 표시하는 값
new_frame: 행동의 결과로 연산된 새 프레임(raw frame, 가공되지 않음)
render_mode가 'rgb_array'로 함수가 실행되었다면, 렌더링된 rgb_array도 리턴한다.
"""
new_frame, reward, terminal, info = self.env.step(action)
# env.setp(action)이 리턴하는 잘 쓰이지 않는 info나 meta 데이터에서 agent가 가진 life의 수를 알 수 있고
# 이를 통해 우리는 life_lost를 판별할 수 있다.
# 이 life_lost를 이용하여 agent가 아무것도 안하는걸 방지하고 게임을 시작하도록 강제할 수 있다.
if info['ale.lives'] < self.last_lives:
life_lost = True
else:
life_lost = terminal
self.last_lives = info['ale.lives']
# 이전에 정의한 process_frame함수를 통해 frame을 연산하고 state에 붙인다.
processed_frame = process_frame(new_frame)
self.state = np.append(self.state[:, :, 1:], processed_frame, axis=2)
# return_mode에 따라 리턴형태를 달리한다.
if render_mode == 'rgb_array':
return processed_frame, reward, terminal, life_lost, self.env.render(render_mode)
elif render_mode == 'human':
self.env.render()
return processed_frame, reward, terminal, life_lost
4. Prioritized experience replay (PER)
ReplayBuffer -> 모델 학습을 위해 상을 메모리에 저장할 것이다.
어떤 상은 다른 상보다 더 중요할 수 있다. 예를 들어 틀린 문제에 집중하는 것 처럼 말이다.
이를 DQN에 적용시켜서 우리는 PER을 적용시켰다. 랜덤하게 상을 선택하는 것 보다 얼마나 중요한 상인지를 바탕으로 상을 선택할 수 있는 방식인데 이는 다음과 같은 방식으로 구현이 된다.
1. 중요도(agent가 틀림)를 수치화 -> TD error (Q-values - EST(Q-values))사용
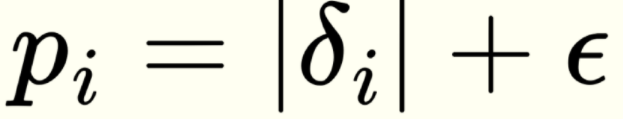
이 값이 확률이 아닌 중요도, 틀림을 수치화한 임의의 스케일된 값임을 명심하자.
이제 이를 확률함수로 만들자.
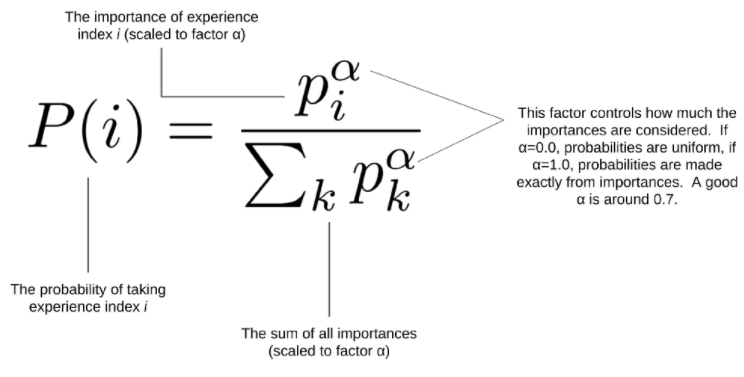
이렇게 표현된 P(i)는 i를 선택할 때의 중요도를 알 수 있을것이다.
이를 PER원문에서는 binary heap을 이용하여 PER를 구현하는것을 추천하였다. 하지만 우리는 단순화를 위해서 다음과 같이 구현할 것이다.
1. add_experience : 메모리에 상을 저장함
2. get_minibatch : 상을 메모리로부터 로드함. 이전에 말한 우선순위 값을 이 함수에서 확인할 수 있을것이다.
5. Agent
이제 Agent를 정의할 것인데, 이전에 정의한 replay buffer와 Q-network를 연결할 것이고 target network를 업데이트 하고 gradient descent를 수행하고 action을 취하는 등의 역할을 취할것이다.
6. Training the agent
네트워크를 학습시킬 것이다.
우선 학습을 위한 파라미터(환경변수)를 정의할 것이고, 이전에 정의한 클래스를 로드할 것이다.
그리고 학습을 하는 main loop를 정의할 것이다.
지금까지 정의한 것들을 DeepMind의 알고리즘과 비교해보자.
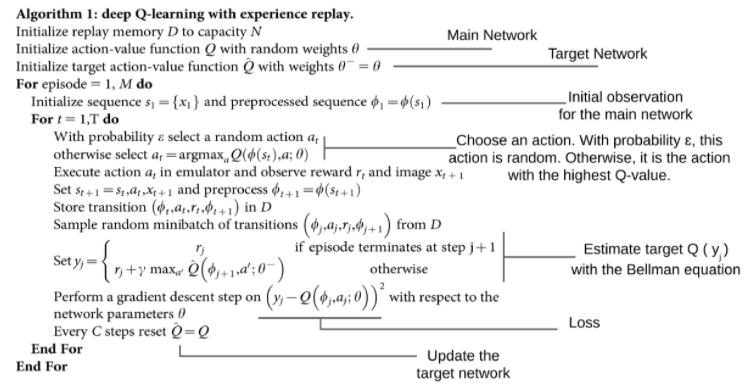
DeepMind의 알고리즘을 앞서 정의한 것이 모두 커버하는 것을 볼 수 있다.
7. 평가
agent가 학습한 것을 평가해보자.
만약 agent가 실시간으로 게임을 플레이하는것을 보고 싶다면 아래의 코드를 사용하라.
ENV_NAME = 'BreakoutDeterministic-v4'
# Create environment
game_wrapper = GameWrapper(ENV_NAME, MAX_NOOP_STEPS)
print("The environment has the following {} actions: {}".format(game_wrapper.env.action_space.n, game_wrapper.env.unwrapped.get_action_meanings()))
# Create agent
MAIN_DQN = build_q_network(game_wrapper.env.action_space.n, LEARNING_RATE, input_shape=INPUT_SHAPE)
TARGET_DQN = build_q_network(game_wrapper.env.action_space.n, input_shape=INPUT_SHAPE)
replay_buffer = ReplayBuffer(size=MEM_SIZE, batch_size=BATCH_SIZE, input_shape=INPUT_SHAPE)
agent = Agent(MAIN_DQN, TARGET_DQN, replay_buffer, game_wrapper.env.action_space.n, input_shape=INPUT_SHAPE)
print('Loading model...')
agent.load('breakout-saves/save-13383/')
print('Loaded')
terminal = True
eval_rewards = []
evaluate_frame_number = 0
for frame in range(EVAL_LENGTH):
if terminal:
game_wrapper.reset(evaluation=True)
life_lost = True
episode_reward_sum = 0
terminal = False
# Breakout require a "fire" action (action #1) to start the
# game each time a life is lost.
# Otherwise, the agent would sit around doing nothing.
action = 1 if life_lost else agent.get_action(0, game_wrapper.state, evaluation=True)
# Step action
_, reward, terminal, life_lost = game_wrapper.step(action, render_mode='human')
evaluate_frame_number += 1
episode_reward_sum += reward
# On game-over
if terminal:
print(f'Game over, reward: {episode_reward_sum}, frame: {frame}/{EVAL_LENGTH}')
eval_rewards.append(episode_reward_sum)
print('Average reward:', np.mean(eval_rewards) if len(eval_rewards) > 0 else episode_reward_sum)
'ML' 카테고리의 다른 글
| ML Agent의 강화학습을 활용한 Unity AI학습 (0) | 2021.05.11 |
|---|---|
| DQN의 입력 (0) | 2021.04.07 |
| TensoFlow를 활용한 DQN 실습 Breakout 적용 - 1 (0) | 2021.04.03 |
| Convolutional layer (ConvNet, CNN) (0) | 2021.04.02 |
| DQN 논문 해석, 분석 (0) | 2021.04.02 |