
1. Feature Detection description matching (기존 SIFT처럼 클래식한)
Vision Transformer를 배우면서 Transformer로 개선 가능한 Vision application이 어떤게 있을지 고민하다가 CG 수업때 흥미롭게 들었던 3D Reconstruction이 떠올랐고, 핵심이던 Feature extraction & matching을 개선할 수 있을까? 에 대한 물음이 생겼었다.

그래서 Corner를 찾고, 비교하는 기존의 방식을 Transformer로 모든 Patch의 Feature를 Extraction하고(Global하고, Context정보를 포함할 것으로 추측함) 두 이미지의 Patch를 비교하면 괜찮지 않을까? 라고 생각해보았다. 근데 이를 조사하는 과정에서 이미 제안된 방법이고 더 세밀하게 제안되어 있는걸 보면서 Transformer가 리딩하고 있긴 하구나 라는 생각을 했었다. 그래서 이번에 이 논문에 대해 발표한걸 다시 정리해보고자한다.
1-1. 간단한 개념
가우시안 커널을 이용한 Blur 이미지 기반으로 edge뽑고, line 걸러서 corner얻은 후 keypoint뽑고, keypoint 주위 pixel로 descriptor만들어서 discriptor간의 matching
1-2. 문제
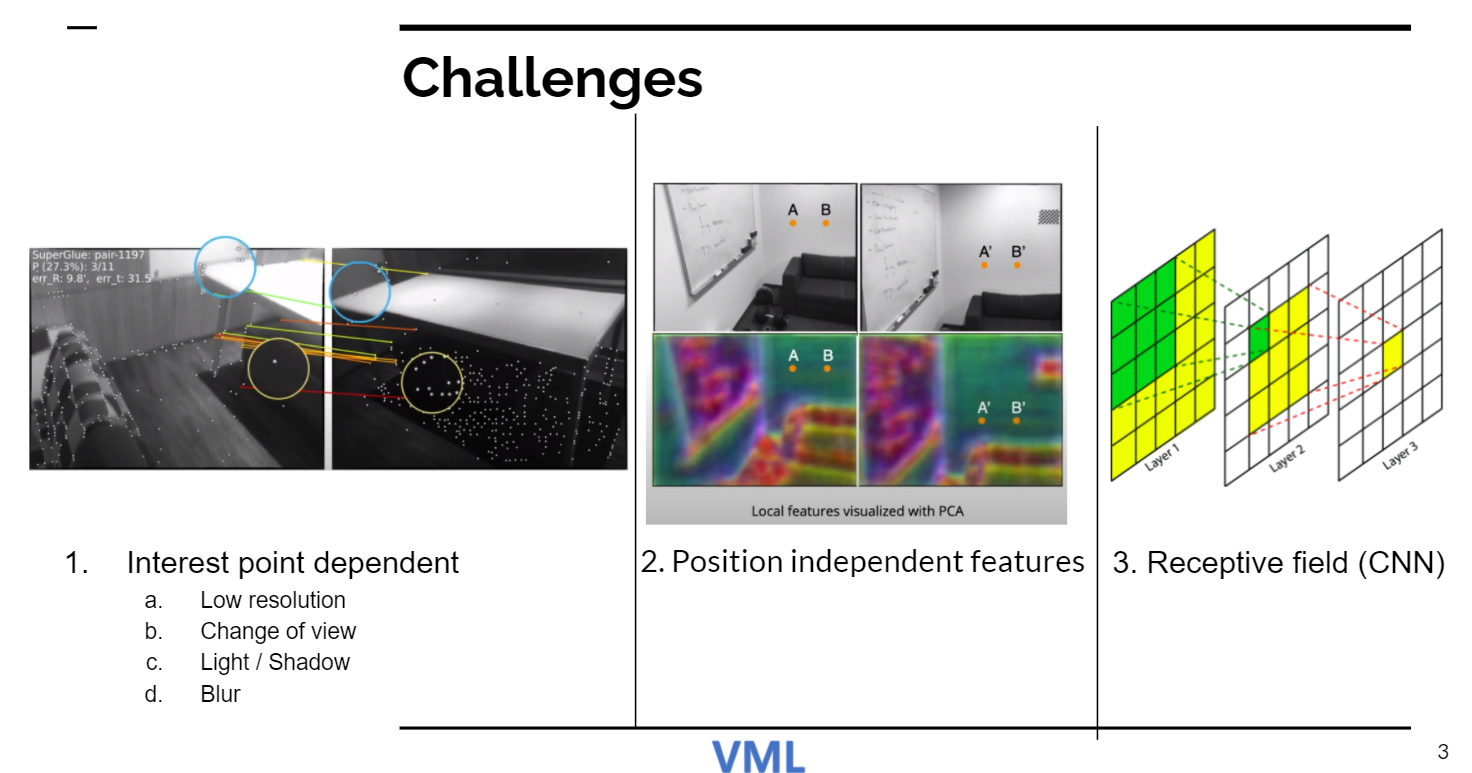
낮은 해상도, view change, 빛 블러 등의 이유로 interest point가 적게 뽑힐 수 있음 (repeatable interest point)
Position dependent하지 않다, 다른 위치, 비슷한 패턴이면 잘봇 매칭됨+ CNN으로 해결하고자 한 시도는 Receptive field때문에 어려웠음
2. LoFRT
feature matching이 data-driven approach로 해결 가능하다는 것이 SuperGlue의 높은 성능으로 알 수 있었으므로 detector free pipeline으로 문제 1을 해결하고 을 해결하고 ransformer의 global receptive field와 positional encoding으로 위치에 의존적인 문맥 정보를 학습하여 문제 2와 3을 해결하자는 것이 취지이다

전체적인 구조를 보면 self level / cross level에서 feature extraction -> 좋은 match의 subpixel들을 matching하여 refine함 -> fine levle matching이 course matche의 location을 refine하는 방식이다.
3. Local Feature CNN
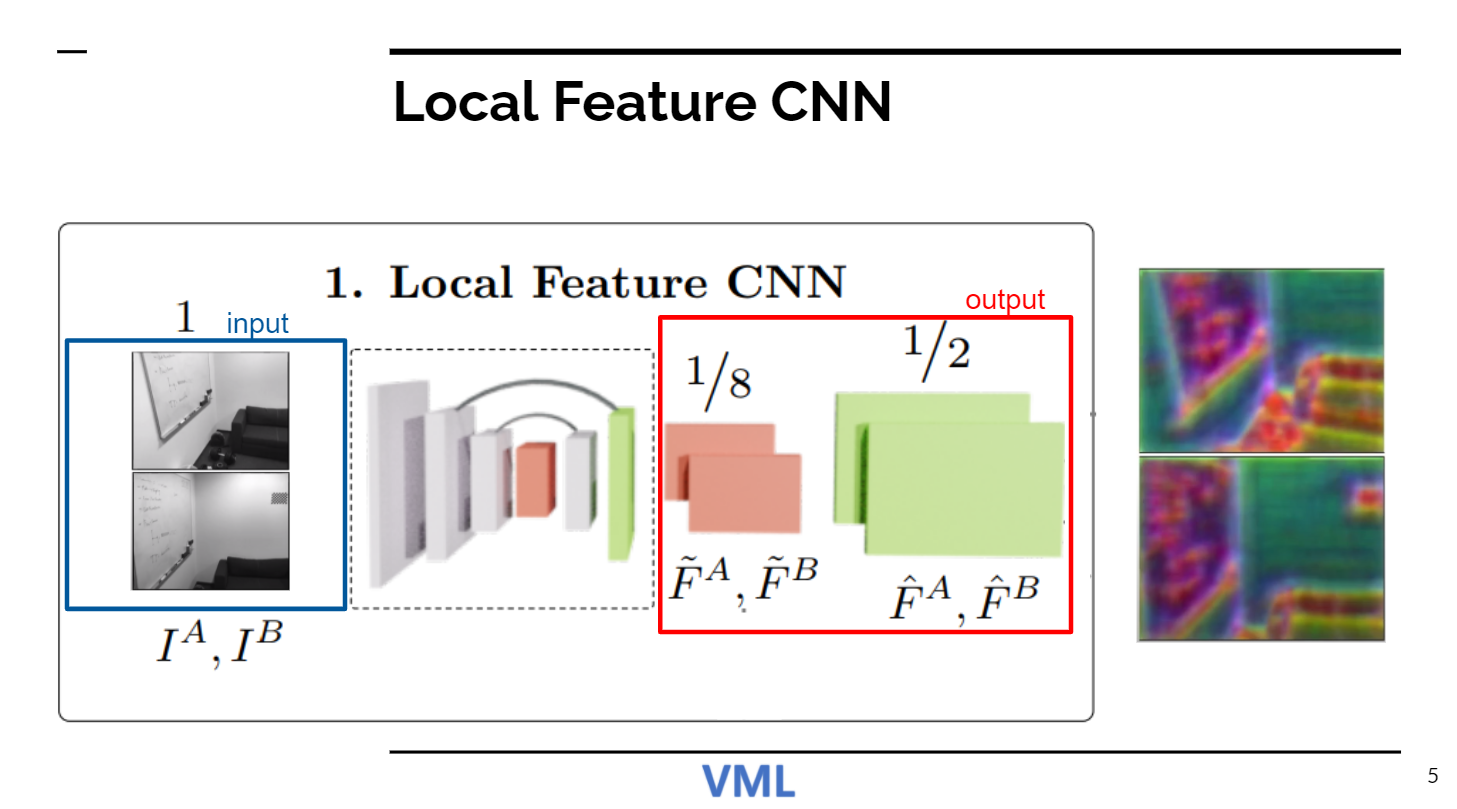
일단 CNN으로 Feature를 뽑는다. 1/8크기의 output을 내는 그냥 Feature extraction 부분은 Transformer를 돌린 결과를 patch-wise feature matching하기 위함이고, 그 1/8을 upsampling한 것은 매칭된 Patch내의 pixel-wise matching을 위함이다.
4. Coarse-Level Local Feature Transform

Coarse-level Loft Module은 CNN가 뽑은 Feature를 두부처럼 patch로 잘라 일반 Transformer처럼 flatten하고, position encoding한 이후 self attention와 cross attention을 몇번 반복한다. 여기서 self attention과 cross attention는 global receptive field를 가진다. self attention과 cross attention의 의도를 보자면 다음과 같다.

우상단의 사진이 Self attention이 학습하는 뉘양스이고, 우하단의 사진이 Cross attention이 학습하는 뉘양스이다. Self attention으로 이미지 내의 문맥을 학습하고, Cross attention으로 원본 이미지와 비교 이미지와간의 문맥을 학습하여 같은 patch끼리 Output을 유사하게 도출한다는 뉘양스이다. (왜냐하면 두 이미지가 달라서 추출될 문맥정보도 다를수 밖에 없기 때문에, 이를 Cross attention을 통해 서로의 문맥을 고려하여 Feature를 비슷하게 만들어 준다는 개념인것 같다)

위 사진을 보면 더 쉽게 이해를 할 수 있을 것이다. 추가로 이전에 말했던 Position에 dependent하게 학습됨도 확인할 수 있다. A와 B가 같은 흰벽임에도 Feature를 PCA를 이용해 Visualize한 결과를 확인해보면 분명히 분리됨을 확인할 수 있다. (position dependent feature representation도 학습될 수 있다. -> local appreance만 아니라 position에 의존될 수 있다.)
5. Differentiable matching
patch끼리 비교해서 score가 높은걸 매칭하는 단계이다.

6. Coarse-to-Fine Module

subpixel level로 refine해주는 모델이다. coarse-level match된 patch의 중심 포인트를 기점으로 두 이미지에서 window size만큼 crop하고, LoFTR의 Transformer를 여러번 돌린 후에 원본 이미지 Patch의 중심과 비교 이미지 Patch의 모든 픽셀을 correlation / softmax로 비교하여 매칭된 Patch내에 실제로 매칭되어야 할 Pixel을 추론한다.
7. Results

꽤나 좋다더라~
난 Self attention으로 뽑은 2개의 Feature를 단순하게 비교하면 될것이다라는 추측과는 다르게 두 이미지간의 Cross Attention을 넣아야 성능이 좋아진다더라~
Patch간의 matching만 생각하고 Patch내에서 매칭될 픽셀을 어떻게 찾아야 할까라고 고민했었는데 Patch내 Pixel간의 Attention연산으로 높은 유사도의 Pixel을 뽑아낼 수 있다더라~ (아래 사진은 LoFTR의 전신인 SuperGlue의 실험 결과)

꽤나 흥미로웠고 나의 부족함에 대해서 느끼게 된 논문이었던거 같다